


دستهبندی نشده
معرفی دیتابیسهای پرکاربرد سیستم بیولوژی
دیتابیس:
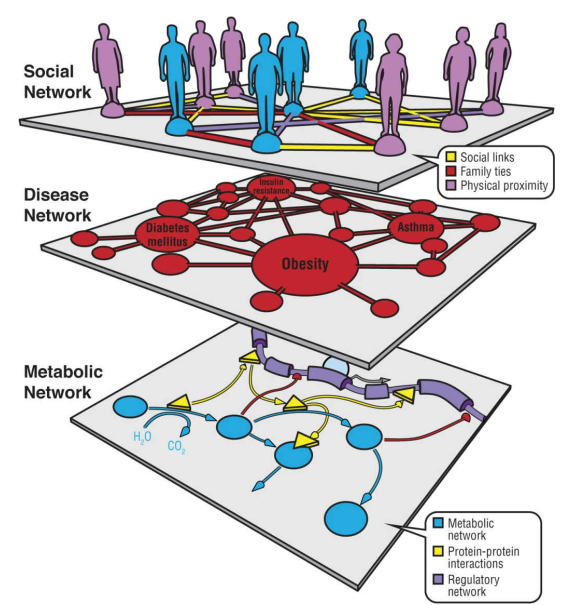
هدف نهایی محققین در حوزه بینرشتهای سیستم بیولوژی حل مسائل بیولوژیکی در سطح کل یک سیستم است. برای اینکه به این هدف دست پیدا کنیم، باید از تلاشهای زیستشناسان در سالهای اخیر بهره ببریم که اطلاعات تجربی و آزمایشگاهی زیادی را تولید کردهاند. با قراردادن این اطلاعات در یک بستر یکپارچه درنهایت به دیتابیسهای پرکاربرد سیستم بیولوژی یا پایگاههای داده زیستشناسی میرسیم. دیتابیسهای زیستی شامل اطلاعات مختلفی در سطوح، ژنومیکس، پروتئومیکس، متابولومیکس و بیان ژن میکرواری هستند و یا اطلاعاتی درمورد فیلوژنی دارند.
به همین دلیل دیتابیسهای زیستی را میتوان بر اساس نوع داده در دستهبندیهای مختلفی موردبررسی قرار داد. مثلاً دیتابیسهای مولکولی شامل توالیها یا مولکولها هستند، دیتابیسهای عملکردی اطلاعاتی درمورد فیزیولوژی، فعالیت آنزیمی و فنوتیپ را در خود جمعآوری کردهاند. دیتابیسهایی که اطلاعات تاکسونومیک را در اختیار دارند نیز برای گونههای مختلف و رتبههای تاکسونومی مورداستفاده قرار میگیرند.
به بیشتر دیتابیسهای زیستی و دیتابیسهای پرکاربرد سیستم بیولوژی از طریق اینترنت دسترسی وجود دارد و علاقهمندان میتوانند درمورد دادههای خود در اینترنت جستوجو انجام دهند و حتی به دیگر دیتابیسها نیز لینک شوند. دیتابیسها با یکدیگر نیز در ارتباط هستند و یک سامانه اصلی را تشکیل دادهاند که اطلاعات را در یکدیگر به هم متصل میکنند و این خود پایگاه دانش بزرگتری را میسازد.
دیتای موجود در دیتابیسها قابل دانلود است و شما از صفحه خود سایت، به کمک سایتهای کمکی یا حتی استفاده از دستورات لینوکس میتوانید این دیتا را دانلود کرده و در سرور یا کامپیوتر شخصی خود تحلیل کنید. دادهها در دیتابیسها فرمتهای مختلفی دارند. مثلاً شما میتوانید دیتای text، دیتای توالی، ساختار پروتئین و لینکها را پیدا کنید. هرکدام از این موارد نیز به فرمت خاصی وجود دارند که میتوانید آن را دریافت کنید.
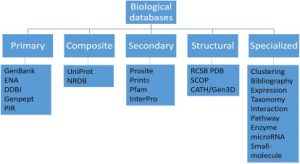
اطلاعات مبتنی بر text را میتوانید در دیتابیسهایی مانند PubMed (دیتابیسی از مقالات در حوزه زیستپزشکی) یا OMIM (دیتابیسی از بیماریهای مختلف) پیدا کنید. دیتای توالی نیز از سایتهایی مانند DDBJ، GenBank و UniProt قابلدسترسی است که دو مورد اول درمورد توالی ژن و مورد آخر درمورد توالی پروتئین است. برای پیداکردن ساختار پروتئین نیز میتوانید از دیتابیسهایی مانند PDB استفاده کنید.
برایآنکه بتوانند دیتای عظیم دیتابیسهای پرکاربرد سیستم بیولوژی را برای مدل یک ارگانیسم متمرکز کنند از فرمت خاصی به نام Systems Biology Markup Language یا بهصورت خلاصه، SBML استفاده میکنند. با بازکردن این فایل، شما میتوانید واکنشها و اجزای آن را در یک فایل بهصورت سیستماتیک و مرتب شده پیدا کنید. هرکدام از این اجزا یا واکنشهایی که آنها را به هم مربوط میکند، به دیتابیسهای لینک داده شدهاند. پس در فایل نتورک متابولیکی یک ارگانیسم، شما میتوانید اطلاعات این دیتابیسها را در کنار یکدیگر و در تعامل با هم پیدا کنید.
دیتابیسهای مختلفی هستند که در حوزه سیستم بیولوژی مورداستفاده قرار میگیرند. مثلاً برایآنکه به دیتابیسی درمورد ریزمتابولیتهای بدن دسترسی داشته باشید باید از دیتابیس HMDB استفاده کنید که خلاصه Human Metabolome Database است. KEGG یکی از مهمترین پایگاههای داده زیستشناسی و یکی از دیتابیسهای پرکاربرد سیستم بیولوژی است که مورداستفاده قرار میگیرد. این پایگاهداده اطلاعات مهمی را در سطوح ژنوم، مسیرهای زیستی (biological pathways)، بیماریها، داروها و محصولات شیمیایی در بر دارد.
این پایگاهداده در حوزه بیوانفورماتیک کاربرد گستردهای دارد و برای آنالیز داده در ژنومیکس، متاژنومیکس، متابولومیکس و غیره کاربرد دارد. همچنین مدلسازی و شبیهسازی در سیستم بیولوژی نیز با کمک دادههای این دیتابیس مهم انجام میگیرد. ساخت این دیتابیس در سال 1995 توسط دانشگاه کیوتو کشور ژاپن کلید خورد و تا به امروز در حال گسترش بوده است.
به دلیل آنکه به یک منبع کامپیوتری برای تحلیل بیولوژیکی دادههای توالی ژنوم نیاز است، kegg pathway نیز فعالیت خود را شروع کرد. این دیتابیس که در دل دیتابیس اصلی KEGG قرار دارد، شامل مسیرهای متابولیکی است که بهصورت دستی ترسیم شده و نشاندهنده یک رابطه بیولوژیک بین اجزای این مسیر زیستی است.
این رابطه از لحاظ تجربی اثبات شده و هر نقشهای در این دیتابیس نشاندهنده شبکهای از تعاملات مولکولی است و ژنها نیز به محصولات خود پیوند داده شدهاند که بیشتر از جنس پروتئین هستند. این دیتا شرایطی را فراهم کرده است که به کمک آن بتوانیم مسیرها و عملکردهای متابولیکی مربوط به ژنها و محصولات آنها را بهتر بشناسیم و استفاده کنیم.
یکی دیگر از دیتابیسهای پرکاربرد سیستم بیولوژی، wikipathway است. این دیتابیس نیز مانند مورد قبل شامل دادههایی درمورد مسیرهای بیولوژیکی است که با سرچ کردن ژن، پروتئین یا یک مسیر زیستی میتوانید به اطلاعات مربوط به آن دسترسی داشته باشید.
این دیتابیس اطلاعاتی درمورد ارگانیسمهای مختلف مانند انسان، باکتریها، مخمر، گونههای گیاهی و c. elegans دارد به همین دلیل کاربردهای دیگری جز زیستپزشکی نیز دارد. BRENDA دیتابیس دیگری است که حاوی اطلاعات مربوط به آنزیمهاست. به کمک این دیتابیس میتوان خواص بیوشیمیایی و کینتیکی آنزیمها، مهارکنندهها، محصولات، مواد اولیه و اطلاعاتی ازایندست را پیدا کنیم.
برای دسترسی به دادههای حاصل از میکرواری میتوانید به GEO مراجعه کنید و دیتای مدنظر خود را بر اساس نوع بیماری، پلتفرم و تعداد نمونههای در دسترس انتخاب کرده و تحلیل کنید. دیتابیسی مانند TargetScan نیز هدف بیولوژیکی miRNAها را پیشبینی میکند.
برای دسترسی به دیتای مربوط به پروسههای بیولوژیکی نیز میتوانید به GO مراجعه کنید. دیتابیسهایی مانند pharmgkb نیز برای حوزه pharmacogenomics طراحی شدهاند. مثلاً در این دیتابیس، ارتباط بین واریانتهای ژنی و نحوه پاسخ بدن به درمانها بررسی میشود.
دیتابیسهای پرکاربرد سیستم بیولوژی در این حوزه یکپارچه شده و برای پاسخ به سؤالات زیستی مورداستفاده قرار میگیرد.
مطالعه صدها مطلب علمی در حوزه بیولوژی
آرشیو جدیدترین خبرهای روز دنیای بیولوژی
