


اطلاعات عمومی,ویکی ژن
یادگیری ماشینی بدون نظارت

مقدمهای بر یادگیری ماشینی بدون نظارت
یادگیری ماشینی بدون نظارت یکی از سه تکنیک اصلی یادگیری ماشینی است که یک الگوریتم یادگیری خود سازمان دهنده است که در آن نیازی به نظارت بر دادهها با ارائه یک مجموعه داده برچسبدار نداریم؛ زیرا در مقایسه با سایر تکنیکهای یادگیری ماشینی مانند یادگیری نظارت شده، میتواند به تنهایی یک الگوی ناشناخته را در مجموعه دادههای بدون برچسب پیدا کند تا با انجام کارهای پیچیده، اطلاعات مفیدی را کشف کند (مانند آنالیز مولفه اصلی و آنالیز خوشهای).
پس بیایید ببینیم چگونه میتوانیم این کار را انجام دهیم! در این مبحث قصد داریم با یادگیری ماشینی بدون نظارت آشنا شویم.
در “یادگیری ماشینی”، همانطور که از اسمش پیداست، ما به ماشینها آموزش میدهیم که کارهایی شبیه به انسان را انجام دهند و همانند انسانها که یا از کسی یا از طریق مشاهده یاد میگیرند، ماشین هم به این روش یاد میگیرد.
یادگیری ماشینی را میتوان به 3 بخش تقسیم کرد:
- یادگیری تحت نظارت
- یادگیری بدون نظارت
- یادگیری تقویتی
انواع یادگیری ماشینی
یادگیری تقویتی یادگیری مبتنی بر عامل است که شامل پاداش و تنبیه بر اساس اقدامات انجام شده توسط یک عامل است. هدف نهایی، ماکسیمم سازی پاداش کلی در فرآیند یادگیری از محیط است.
بهطور خلاصه وقتی دادههای ورودی-خروجی دارید، دادههای برچسب گذاری شده (برای مثال دادههای قد و وزن برای تعیین اینکه آیا یک فرد مرد است یا زن) میتواند به عنوان یک کار یادگیری تحت نظارت (در مورد انسان یادگیری از شخص) در نظر گرفته شود.
اما در بسیاری از سناریوهای زندگی واقعی، این دادههای برچسب گذاری یا حاشیه نویسی شده همیشه در دسترس نیستند. در نتیجه، بارها با مشکلات دسته بندی اشیا بر اساس ویژگیهایشان که به صراحت ذکر نشدهاند، مواجه میشویم. پس چگونه این مشکل را حل کنیم؟ خب، جواب یادگیری بدون نظارت است.
ویکیپدیا میگوید یادگیری بدون نظارت نوعی از یادگیری هب (Hebbian learning) خود سازمانیافته است که به یافتن الگوها در مجموعه دادههای ناشناخته بدون برچسبهای از قبل موجود کمک میکند. در یادگیری بدون نظارت، ما هیچ اطلاعات برچسبی نداریم، اما با این وجود، میخواهیم از دادهها بر اساس ویژگیهای مختلف آن اطلاعاتی به دست آوریم.
انواع یادگیری ماشینی بدون نظارت
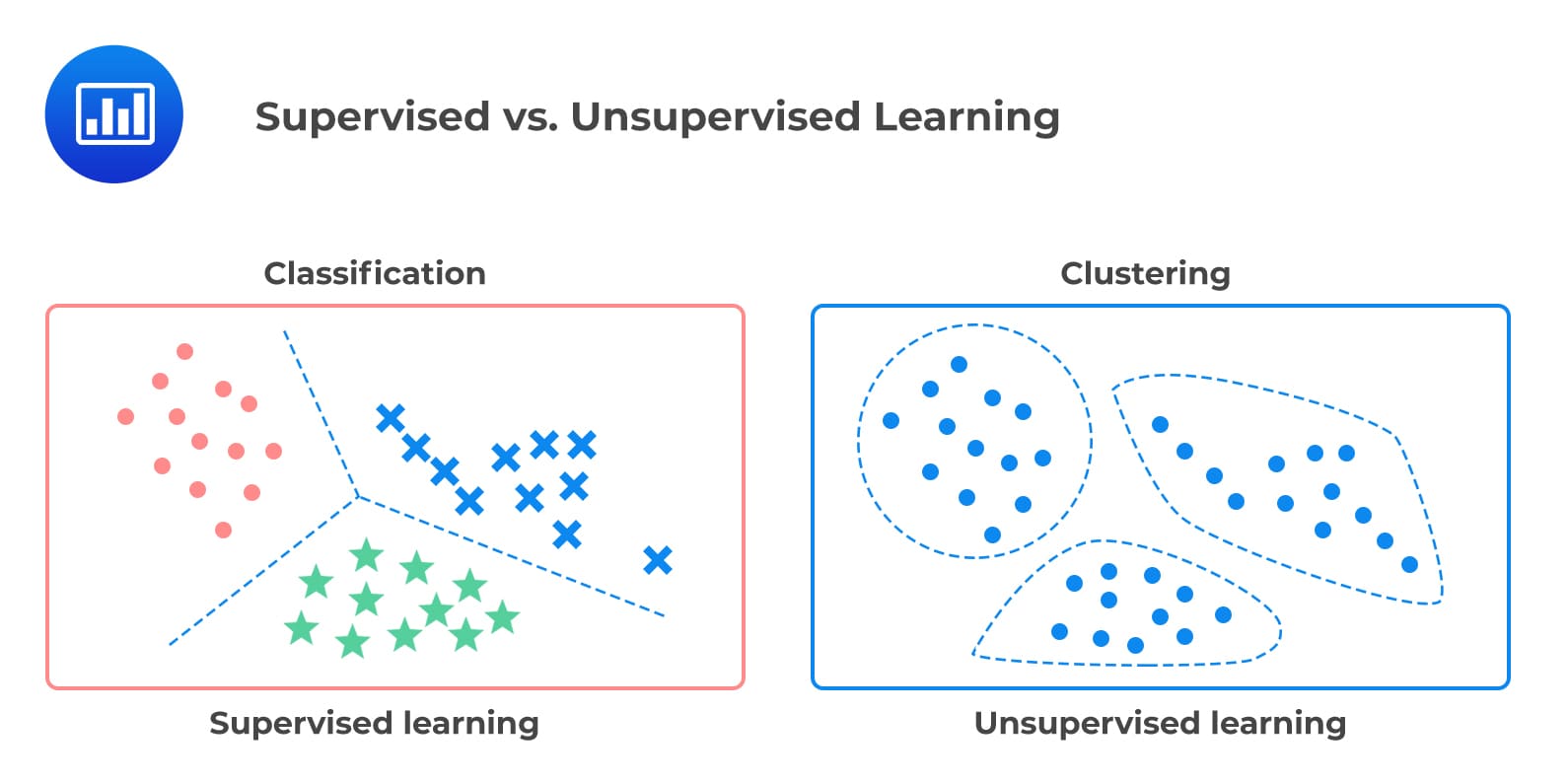
وظایف یادگیری بدون نظارت را میتوان به طور کلی به 3 دسته تقسیم کرد:
- کاوش قواعد وابستگی ((ARM) Association rule mining)
- خوشه بندی (Clustering)
- سیستم توصیه گر(Recommendation system)
- کاوش قواعد وابستگی
هنگامی که ما دادههای تراکنشی برای چیزی داریم، این دادهها میتوانند برای محصولات فروخته شده یا هر داده تراکنشی مربوط به آن باشند. میخواهیم بدانیم آیا رابطه پنهانی بین خریدار و محصول یا محصول با محصول وجود دارد، به گونهای که بتوانیم به نحوی از این اطلاعات برای افزایش فروش خود استفاده کنیم. استخراج این روابط هسته روش کاوش قواعد وابستگی است. میتوانیم از الگوریتمهای AIS، SETM، Apriori، FP برای استخراج روابط استفاده کنیم.
- خوشه بندی
خوشه بندی را میتوان بر روی هر دادهای که اطلاعات کلاس یا برچسب را نداریم اعمال کرد. ما میخواهیم دادهها را طوری گروه بندی کنیم که مشاهدات با ویژگیهای مشابه متعلق به یک خوشه یا گروه باشند و فاصله بین خوشهای باید ماکزیمم باشد. در عین حال، فاصله درون خوشهای باید مینیمم باشد. برای مثال میتوانیم دادههای رأی دهندگان را برای تعیین نظر در مورد دولت، محصولات بر اساس ویژگیها و کاربردشان، تقسیم بندی جمعیت بر اساس ویژگی درآمدی در فروش و بازاریابی، خوشه بندی کنیم.
ما میتوانیم از ابزارهایی نظیر K-Means، K-Means++، K-Medoids، Fuzzy C-means (FCM) ، همچنین الگوریتمهایی نظیر Expectation-Maximisation (EM)، خوشه بندی تجمعی (Agglomerative Clustering) ، DBSCAN، انواع خوشه بندی سلسله مراتبی (Hierarchical Clustering) به عنوان روش خوشه بندی تک اتصالی، اتصال کامل، اتصال میانی، الگوریتمهای روش وارد (Ward’s method algorithms) برای خوشه بندی، استفاده کنیم.
- سیستم توصیه گر
سیستم توصیه گر اساساً بسط و گسترش کاوش قواعد وابستگی است. در این روش در حال استخراج روابط در ARM (کاوش قواعد وابستگی) هستیم. در سیستم توصیه گر، ما از این روابط برای توصیه چیزی استفاده میکنیم که شانس پذیرش بالاتری توسط کاربر نهایی دارد. پس از اعلام جایزه بزرگ 1,000,000 دلاری در سال 2009 توسط نتفلیکس، سیستمهای توصیه گر محبوبیت پیدا کردند.
سیستم توصیه گر روی دادههای تراکنشی کار میکند، اعم از تراکنش مالی، تجارت الکترونیک، یا تراکنشهای فروشگاههای مواد غذایی. امروزه، بازیگران بزرگ در صنعت تجارت الکترونیک، با ارائه توصیههای سفارشی برای هر کاربر بر اساس سابقه خرید قبلی و دادههای مربوط به رفتارهای مشابه در خرید از سوی سایر کاربران، مشتریان را اغوا میکنند.
روشهای توسعه سیستمهای توصیه گر را میتوان به طور کلی به فیلتر مشارکتی (Collaborative filtering) و فیلتر محتوا محور (Content-Based filtering) تقسیم کرد. در فیلتر مشارکتی، ما فیلتر مشارکتی کاربر-کاربر و فیلتر مشارکتی آیتم-آیتم را داریم که رویکردهای مبتنی بر حافظه هستند و همچنین ماتریس عامل بندی (Matrix factorization) و تجزیه مقادیر منفرد (Singular Value Decomposition (SVD)) که رویکردهای مبتنی بر مدل هستند را داریم.
کاربردهای یادگیری ماشینی بدون نظارت
از آنجایی که دادههای جهان هر روز به شدت در حال افزایش است، یادگیری بدون نظارت کاربردهای زیادی دارد. ما همواره با استفاده از پلتفرمهای رسانههای اجتماعی یا تولید محتوای ویدیویی در یوتیوب در حال ایجاد دادهها هستیم و بسیاری از اوقات حتی عمداً این کار را انجام نمیدهیم. همه این دادهها بدون ساختار هستند و برچسب زدن به آنها برای امورات مربوط به یادگیری تحت نظارت، خستهکننده و پرهزینه خواهد بود.
در زیر برخی از کاربردهای جالب یادگیری ماشین بدون نظارت آورده شده است:
خواربارفروشی یا فروشگاه/بازار تجارت الکترونیک: قواعد وابستگی را از دادههای معاملاتی مشتریان استخراج کرده و توصیههایی برای خرید محصولات به مصرفکنندگان ارائه میدهد.
پلتفرم رسانههای اجتماعی: روابط با کاربران مختلف برای پیشنهاد محصولات یا خدمات استخراج میکند. به افراد جدید ارتباط اجتماعی را توصیه میکند.
خدمات: ارائه پیشنهادهایی برای خدمات مسافرتی، پیشنهاد خانههایی برای اجاره یا خدمات مراسم ازدواج.
بانکداری: مشتریان را بر اساس تراکنشهای مالی آنها خوشه بندی میکند. تراکنشهای مشکوک را برای کشف تقلب خوشه بندی میکند.
سیاست: نظرات رای دهندگان در مورد شانس پیروزی یک حزب خاص را خوشه بندی میکند.
بصری سازی داده: با خوشه بندی و روش t-distributed Stochastic Neighbor Embedding (t-SNE) میتوانیم دادههای با ابعاد بالا را به تصویر بکشیم. همچنین، این روش میتواند برای کاهش ابعاد استفاده شود.
سرگرمی: ارائه پیشنهادهایی برای فیلم و موسیقی، همانطور که نتفلیکس و آمازون این کار را انجام میدهند.
بخش بندی تصویر: خوشهبندی بخشهای تصویر بر اساس نزدیکترین مقادیر پیکسلی.
محتوا: روزنامههای شخصیسازی شده، پیشنهادهای صفحات وب، برنامههای آموزش الکترونیکی و فیلترهای ایمیل.
کشف ساختاری: با خوشه بندی میتوانیم هر ساختار پنهانی را در دادهها کشف کنیم همانند خوشه بندی دادههای توییتر برای تجزیه و تحلیل احساسات.
نتیجه گیری
یادگیری ماشینی بدون نظارت خیلی قابل اندازهگیری نیست، اما میتواند بسیاری از مشکلاتی را که در آن الگوریتمهای نظارت شده با شکست مواجه میشوند، حل کند. کاربردهای زیادی برای یادگیری بدون نظارت در بسیاری از حوزهها که در آن دادههای بدون ساختار و بدون برچسب داریم، وجود دارد.
ما میتوانیم از تکنیکهای یادگیری بدون نظارت استفاده کنیم تا به ماشینهایمان بیاموزیم که بهتر از ما کار کنند. در سالهای اخیر، ماشینها در زمینه اموراتی که قرنها توسط انسانها حل شده تلقی میشدند، بهتر از انسان عمل کردهاند. امیدوارم با این مقاله متوجه شده باشید که یادگیری ماشینی بدون نظارت چیست و چگونه میتوان از تکنیکهای آن برای حل مسائل دنیای واقعی استفاده کرد.
از دوره های کارآموزی ژنیران دیدن فرمایید:
مترجم: فاطمه فریادرس
