


دستهبندی نشده
مقدمهای بر روشهای یادگیری ماشین
روشهای یادگیری ماشین که یادگیری سیستم با استفاده از روشهایی مانند یادگیری نظارتی و یادگیری بدون نظارت انجام میشوند، بیشتر در روشهایی مانند طبقهبندی، رگرسیون و دستهبندی ردهبندی میشوند. با توجه به نوع مجموعه دادهای که برای آموزش مدل در دسترس است روش مناسبتر را انتخاب میکنیم، زیرا مجموعه داده میتواند با برچسب، بدون برچسب و بزرگ باشد. کاربردهای مختلفی (مانند طبقهبندی تصویر، تجزیه و تحلیل پیشبینی ، تشخیص اسپم) وجود دارد که از روشهای مختلف یادگیری ماشین استفاده میکند.
ماشین ها چگونه یاد میگیرند؟
روش های مختلفی برای انجام آن وجود دارد. اینکه کدام روش به طور کامل دنبال شود به بیان مسئله بستگی دارد. بسته به مجموعه داده، و مشکلی که وجود دارد، دو راه متفاوت برای پیبردن به عمق مسئله وجود دارد. یکی یادگیری نظارتی و دیگری یادگیری بدون نظارت. نمودار زیر طبقهبندی بیشتر روشهای یادگیری ماشین را توضیح میدهد. در مورد آنها یکی یکی بحث خواهیم کرد.
به نمودار زیر دقت کنید!
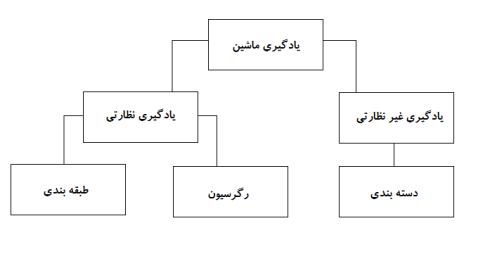
بیایید بفهمیم که یادگیری نظارتی به چه معناست.
یادگیری نظارتی
همانطور که از نام آن پیداست، تصور کنید معلم یا سرپرستی به شما در یادگیری کمک میکند. در مورد ماشین آلات هم همینطور است. ما ماشین را با استفاده از دادههایی که برچسب گذاری شده اند آموزش میدهیم .
برخی از جالب ترین کاربردهای آموزش نظارتی عبارتند از:
تجزیه و تحلیل احساسات (توئیتر، فیس بوک، نتفلیکس، یوتیوب و غیره)
پردازش زبان طبیعی
دستهبندی تصویر
تحلیل پیشگو
تشخیص الگو
تشخیص اسپم
پردازش متوالی گفتار
در حال حاضر، یادگیری نظارتی بیشتر به طبقهبندی و رگرسیون تقسیم میشود. بیایید، این روشها را بیشتر بشناسیم.
طبقه بندی
طبقهبندی روند یافتن روشی است که به جداسازی دادهها در دسته بندی های مختلف کمک میکند. در این فرآیند، دادهها با توجه به برخی پارامترهای داده شده در ورودی، تحت برچسبهای مختلف دسته بندی میشوند و سپس برچسبها برای دادهها پیشبینی میشوند. دستهبندی یعنی متغیر خروجی، یک دسته است، یعنی قرمز یا سیاه، اسپم یا غیر اسپم، دیابتی یا غیر دیابتی و غیره.
مدلهای طبقهبندی شامل ماشین بردار پشتیبانی (SVM)، K-نزدیکترین همسایه (KNN)، Naive Bayes و غیره است.
الف) دستهبندی ماشین بردار پشتیبان (SVM)
SVM یک روش یادگیری نظارتی است که دادهها را بررسی میکند و آنها را به یکی از دو دسته طبقهبندی میکند. من از یک هایپرپلین برای دستهبندی دادهها استفاده میکنم. یک طبقهبندیکننده متمایز خطی تلاش میکند تا خط مستقیمی را ترسیم کند که دو مجموعه داده را از هم جدا میکند و در نتیجه مدلی برای طبقهبندی ایجاد میکند. در واقع سعی میکند یک خط یا منحنی (در دو بعد) یا یک منیفولد (در چند بعد) پیدا کند که دستهها را از یکدیگر جدا کند.
ب) روش طبقهبندی kنزدیکترین همسایه (KNN)

اگر اسم این روش را با دقت بخوانید، خود اسم نشان می دهد که الگوریتم چه کاری انجام می دهد. KNN نقاط دادهای را که نزدیکتر هستند، توسط ویژگیهای مشابهی که دارند و به احتمال زیاد به همان دسته همسایه تعلق دارند، در بر میگیرد. برای هر نقطه داده جدید، فاصله تا تمام نقاط داده دیگر محاسبه میشود و دسته بر اساس K نزدیکترین همسایه تعیین میشود. بله، ممکن است غیرقابل باور به نظر برسد، اما این روش برای برخی از طبقهبندیها، همه کاره به حساب می آید.
یک نقطه داده با میزان بیشتر شباهتی که با همسایگانش دارد طبقهبندی میشود، سپس نقطه داده به نزدیکترین دسته در بین k-همسایگان آن اختصاص داده میشود.
در KNN، هیچ مدل یادگیری مورد نیاز نیست و همه کارها در زمانی اتفاق میافتد که یک پیشبینی درخواست میشود. به همین دلیل است که KNN اغلب به عنوان یک الگوریتم یادگیری تنبل شناخته میشود.
ج) طبقهبندی کننده ساده بیز Bayes
طبقهبندی بیز یک الگوریتم یادگیری ماشین است که به شدت برای مشکلات دستهبندی متن پیشنهاد میشود. این بر اساس قضیه احتمال بیز است. این دسته بندی کنندهها ساده نامیده میشوند زیرا فرض میکنند که متغیرهای ویژگی مستقل از یکدیگر هستند. این بدان معناست که، برای مثال، ما یک جمله کامل برای ورودی داریم، سپس Naive Bayes هر کلمه در یک جمله را مستقل از سایر کلمات فرض میکند. و سپس آنها را بر اساس آن طبقهبندی میکند. می دانم، به نظر خیلی ساده به نظر میرسد، اما یک انتخاب عالی برای رفع مشکلات دستهبندی متن و یک انتخاب محبوب برای طبقه بندی ایمیلهای اسپم است.
انواع مختلفی از الگوریتمهای ساده بیز مانند BernoulliNB، GaussianNB، MultinomialNB را ارائه میدهد.
این الگوریتم تمام ویژگیها را به هم نامرتبط میداند، بنابراین نمیتواند رابطه بین ویژگیها را بیاموزد. به عنوان مثال، فرض کنید، وارون دوست دارد همبرگر بخورد، او همچنین دوست دارد سیب زمینی سرخ کرده با نوشابه بخورد. اما دوست ندارد همبرگر و ترکیب سیب زمینی سرخ کرده با نوشابه را با هم بخورد. در اینجا، Naive Bayes نمیتواند رابطه بین دو ویژگی را بیاموزد، بلکه فقط اهمیت ویژگیهای فردی را میآموزد.
حالا بیایید به سمت دیگر روش یادگیری نظارتی خود برویم، که رگرسیون است.
رگرسیون
رگرسیون فرآیند یافتن نمونه است که به تفکیک دادهها با استفاده از مقادیر پیوسته کمک میکند. در این، ماهیت دادههای پیشبینی شده مرتب میشود. برخی از پرکاربردترین مدلهای رگرسیون شامل رگرسیون خطی، جنگل تصادفی (درخت تصمیم)، شبکههای عصبی برنامه ای کامپیوتری است.
رگرسیون خطی
یکی از سادهترین رویکردها در یادگیری نظارتی میباشد که برای پیشبینی پاسخ کمیتی مفید است.
رگرسیون خطی شامل یافتن بهترین خط مستقیم از طریق نقاط است. بهترین خط را خط رگرسیون مینامند. بهترین خط مناسب دقیقاً از تمام نقاط داده عبور نمیکند، بلکه سعی میکند بهترین خط را به آنها نزدیک کند.
این الگوریتم برای دادههای پیوسته پرکاربرد است. با این حال، تنها بر میانگین متغیر وابسته تمرکز میکند و خود را به یک رابطه خطی محدود میکند.
رگرسیون خطی را میتوان برای سریهای زمانی و پیش بینی روند استفاده کرد. این روش میتواند میزان فروش آینده را بر اساس دادههای قبلی پیشبینی کند.
یادگیری بدون نظارت
یادگیری بدون نظارت مبتنی بر رویکردی است که می توان آن را غایب بودن معلم نامید و در نتیجه معیاری برای خطای مطلق در نظر گرفت. زمانی به کار میاید که نیاز به نوع یادگیری طبقه بندی یا گروه بندی بخشها باشد. عناصر را می توان با توجه به شباهت آنها گروهبندی (طبقه بندی) کرد.
در یادگیری بدون نظارت، دادهها بدون برچسب هستند، دسته بندی نمیشوند و الگوریتمهای سیستم بدون آموزش قبلی روی دادهها عمل میکنند. الگوریتمهای یادگیری بدون نظارت میتوانند وظایف پیچیدهتری را نسبت به الگوریتمهای یادگیری نظارتی انجام دهند.
یادگیری بدون نظارت شامل طبقه بندی است که میتواند با استفاده از K به معنای طبقهبندی، سلسله مراتبی، مخلوط گاوسی، مدل پنهان مارکوف انجام شود.
برنامههای آموزشی بدون نظارت عبارتند از:
تشخیص شباهت
برچسب زدن خودکار
تقسیمبندی داده (مانند شخص، حیوان، فیلم)
دستهبندی
دستهبندی یک تکنیک یادگیری بدون نظارت است که برای تجزیه و تحلیل دادهها در بسیاری از زمینهها استفاده میشود. الگوریتم دستهبندی زمانی مفید است که بخواهیم بینش دقیقی در مورد دادههای خود به دست آوریم.
یک مثال واقعی از دستهبندی، دستههای ژانر نتفلیکس است که برای مشتریان، اهداف مختلف از جمله علایق، جمعیتشناسی، سبک زندگی و غیره تقسیمبندی میشوند. حالا میتوانید به این فکر کنید که زمانی که شرکتها میخواهند اهمیت باشگاه مشتریان خود را درک کنند و مشتریان جدید را مورد هدف قرار دهند , دستهبندی چقدر مفید به نظر میرسد .
الف) K به معنای دستهبندی است
K یعنی الگوریتم دسته بندی سعی میکند دادههای ناشناخته داده شده را بین دستهها تقسیم کند. بهطور تصادفی، مرکز دستههای «k» را انتخاب میکند، فاصله بین نقاط داده و مرکز دسته ها را محاسبه میکند و در نهایت نقطه داده را به مرکز دسته ای که فاصله آن کمتر از همه مرکز دستهها است، اختصاص میدهد.
در k-means، گروهها با نزدیکترین مرکز برای هر گروه تعریف میشوند. این مرکز بهعنوان «مغز» الگوریتم عمل میکند، آنها نقاط دادهای را که به آنها نزدیکترین هستند، میگیرند و سپس آنها را به خوشهها اضافه میکنند.
ب) دستهبندی سلسله مراتبی
دستهبندی سلسله مراتبی تقریباً شبیه دستهبندی معمولی است مگر اینکه بخواهید سلسله مراتبی از دستهها ایجاد کنید. این میتواند زمانی مفید باشد که میخواهید تعداد خوشهها را تعیین کنید. به عنوان مثال، فرض کنید در حال ایجاد گروه هایی از اقلام مختلف در فروشگاه آنلاین مواد غذایی هستید. در صفحه اصلی اول، شما چند آیتم گسترده میخواهید و با کلیک بر روی یکی از موارد، دستههای خاص، یعنی خوشههای خاصتری باز میشوند.
کاهش ابعاد
کاهش ابعاد را میتوان به عنوان فشرده سازی یک فایل در نظر گرفت. این به این معنی است که اطلاعاتی را که مرتبط نیستند، خارج کنید. پیچیدگی دادهها را کاهش میدهد و سعی میکند دادههای معنی دار را حفظ کند. به عنوان مثال، در فشردهسازی تصویر، ابعاد فضایی را که تصویر در آن به همان شکلی که هست میماند، بدون از بین بردن بیش از حد محتوای معنیدار تصویر، آن را کاهش میدهیم.
PCA برای تجسم دادهها
تجزیه و تحلیل مؤلفه اصلی (PCA) یک روش کاهش ابعاد است که میتواند برای تجسم دادههای شما مفید باشد. PCA برای فشردهسازی دادههای ابعاد بالاتر به دادههای با ابعاد پایینتر استفاده میشود، یعنی میتوانیم از PCA برای کاهش دادههای چهار بعدی به سه یا دو بعد استفاده کنیم تا بتوانیم دادهها را تجسم کنیم و درک بهتری از آنها داشته باشیم.
آرشیو اخبار و مطالب علمی ژنیران