


دستهبندی نشده
یادگیری بدون نظارت
یادگیری بدون نظارت: تقریبا 20 سال از قرن 21 می گذرد. دنیای ما به طور چشمگیری به واسطه ی محاسبات مدرن تغییر شکل یافته است و در حال حاضر همه ی صنایع بر اساس کاربرد هوش مصنوعی پایه گذاری شده اند. اگرچه تعاریف متعددی برای AI وجود دارد، ما به قابلیت کلی یک ماشین (برای مثال، یک کامپیوتر) برای تکرار مستقل فرایند شناختی معمول انسان در تصمیم گیری به پاسخ به محیط مفروض خود به منظور دستیابی به هدف از پیش تعیین شده اشاره می کنیم.
در دنیای امروز ما با کامپیوتر های مبتنی بر تکنولوژی AI مواجه هستیم: گوشی های هوشمند، موتور های جست و جوگر، کانال های شبکه های اجتماعی، تبلیغات شخصی شده، شناسایی صوت و تصویر، ماشین های خودران، توالی یابی ژنومی، ساختمان های با مصرف بهینه انرژی، بازی های کامپیوتری، ترجمه ی زبان و مثال های فراوان دیگر.
آن چیزی که “انقلاب صنعتی چهارم” نامیده می شود، در دهه ی 1930 آغاز شد و از طریق کار افرادی مانند آلن تورینگ در طول جنگ جهانی دوم و بعد از آن تا پیشرفت های اساسی قرن 21 در تراشه های ریزپردازش ، جمع آوری داده ها ، قدرت ذخیره سازی ، ظرفیت بازیابی و شبکه، رشد چشمگیری داشت. همه این پیشرفت ها چالشی برای مردم ، از جمله پزشکان و جامعه مراقبت های بهداشتی ، برای ادامه دادن و انطباق با این میزان رو به افزایش تغییر است.
یادگیری ماشین(ML) در یادگیری بدون نظارت چیست؟
یادگیری ماشین(ML) شامل توسعه و استقرار الگوریتم هایی است که بجای برنامه ریزی صریح برای تعیین خروجی های خاص (اقدامات) در پاسخ به ورودی های خاص (محیط درک شده) ، داده ها و خصوصیات آن را تجزیه و تحلیل می کند و – به طور معمول – از ابزارهای آماری برای تعیین اقدامات استفاده می کند.
الگوریتم های ML پویا هستند و با معرفی بیشتر داده ها تمایل دارند بهتر شوند و یا “یاد گیرند”. بیشتر الگوریتم های ML را می توان به عنوان مدل های ریاضی مشاهده کرد که مجموعه ای از متغیرهای مشاهده شده ، شناخته شده به عنوان “ویژگی ها” یا “پیش بینی ها”، از یک نقطه داده یا نمونه را در مجموعه ای از متغیرهای نتیجه ، معروف به “برچسب ها” یا “اهداف” تصویر می کنند. الگوریتم ها در فرایندی که تحت عنوان “آموزش” شناخته می شود، بهینه شده اند تا بتوانند با تجزیه و تحلیل ویژگی های صریح، برچسب ها را پیش بینی کنند.
به عنوان مثال، در یک طبقه بندی کننده که درجه تصاویر هیستوپاتولوژیک از بافت پروستات را پیش بینی می کند، یک نمونه یک تصویر اسلاید دیجیتالی است، ویژگی ها ممکن است مقادیر رنگی پیکسل های مشاهده شده و برچسب ها درجه های گلیسون اختصاص داده شده به بافت در تصویر اسکن شده باشند.
تکنیک های ML را می توان به طور کلی با توجه به نوع برچسب و نوع ویژگی طبقه بندی کرد. بر اساس برچسب ها، ML را می توان به سه الگوی یادگیری نظارت شده، بدون نظارت و تقویتی تقسیم کرد. بر اساس ویژگی ها، ML را می توان به روش های مبتنی بر ویژگی های دست ساز یا غیر دست ساز طبقه بندی کرد.
یادگیری بدون نظارت
در یادگیری بدون نظارت، الگوریتم بر اساس ویژگی های داده های آموزش به تنهایی، بدون برچسب های مربوطه، نمونه ها را به طبقات مختلف تقسیم می کند. نمونه هایی از این الگوریتم ها خوشه بندی k-means برای کشف گروه هایی از نمونه های مشابه در داده های ارائه شده، تجزیه و تحلیل مولفه های اصلی و خود رمزگذاران است. یک مثال از یادگیری بدون نظارت کاربردی، الگوریتمی است که الگوهای منحصر به فرد تغییرات هیستون را در نمونه های سرطانی پروستات با رنگ آمیزی ایمونوهیستوشیمی شناسایی می کند که مستقل از پارامترهای بالینی تثبیت شده مانند مرحله تومور یا PSA خطر عود را پیش بینی می کند.
k-means clustering
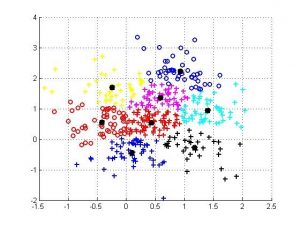
K-means clustering به طور گسترده ای به عنوان یک طرح از بالا به پایین پذیرفته شده است، KMC به دنبال یک پارتیشن است که میانگین مربع فشرده سازی (MSC)، که میانگین فاصله مربع بین مرکز خوشه و اعضای آن است را به حداقل برساند. به طور خاص، KMC مراحل زیر را انجام می دهد. 1) مراکز خوشه K را با انتخاب K توسط کاربر، شروع می کند. 2) هر نمونه را به نزدیکترین مرکز خوشه اختصاص می دهد و سپس مرکز خوشه را با میانگین نمونه های اختصاص داده شده به روز می کند. 3) دو مرحله را در مرحله 2 تکرار می کند تا پارتیشن همگرا شود. در شکل زیر نمونه ای از خروجی الگوریتم K-means clustering نشان داده شده است.
شکل 2 : فضای نمونه به کمک الگوریتم K-means clustering بخش بندی شده است.
Hierarchical clustering و یادگیری بدون نظارت
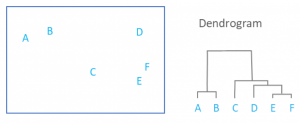
خوشه بندی سلسله مراتبی که به آن تحلیل خوشه سلسله مراتبی نیز گفته می شود، الگوریتمی است که اشیاء مشابه را در گروه هایی به نام خوشه گروه بندی می کند. نقطه پایانی مجموعه ای از خوشه ها است که در آن هر خوشه از یک خوشه دیگر متمایز است و اشیاء درون هر خوشه به طور کلی شبیه به یکدیگر هستند.
خوشه بندی سلسله مراتبی با در نظر گرفتن هر مشاهده به عنوان یک خوشه جداگانه شروع می شود. سپس، دو مرحله زیر را به طور مکرر اجرا می کند: (1) شناسایی دو خوشه که نزدیکترین آنها به هم هستند و (2) ادغام دو خوشه مشابه. این روند تکراری تا زمانی که همه خوشه ها با هم ادغام شوند ادامه می یابد.
خروجی اصلی خوشه بندی سلسله مراتبی یک دندروگرام است که رابطه سلسله مراتبی بین خوشه ها را نشان می دهد:
مطالعه صدها مطلب علمی در حوزه بیولوژی
آرشیو جدیدترین خبرهای روز دنیای بیولوژی
