


دستهبندی نشده
مقدمهای بر چرخه زندگی یادگیری ماشینی (ML)

چرخه زندگی یادگیری ماشینی به عنوان یک فرآیند چرخه ای تعریف میشود که شامل سه مرحله :
( توسعه پایپلاین، مرحله آموزش و مرحله نتیجهگیری) است که توسط دادهشناس و مهندسان داده برای توسعه، آموزش و ارائه مدلها با استفاده از حجم عظیمی از دادهها به دست میآید. همچنین در کاربردهای مختلفی دخیل هستند تا سازمان بتواند از هوش مصنوعی و الگوریتمهای یادگیری ماشین برای به دست آوردن ارزش تجاری عملی استفاده کند. پایپلاین وسیله ای درون CPU که آن را قادر به خواندن دستورها قبل از اجرا میکند به طوری که هر گاه دستوری کامل شد دستور بعدی آماده ی اجرا باشد
اولین گام در چرخه زندگی یادگیری ماشینی شامل تبدیل دادههای اولیه به یک مجموعه داده پاکسازی شده است، که این مجموعه داده اغلب به اشتراک گذاشته و دوباره استفاده میشود. اگر یک تحلیلگر یا یک دادهشناس در دادههای دریافتی با مشکلاتی مواجه شود، باید به دادههای اصلی و اسکریپتهای تبدیل دسترسی داشته باشد. دلایل مختلفی وجود دارد که ممکن است بخواهیم به نسخههای قبلی مدلها و دادههای خود بازگردیم.
برای مثال، یافتن بهترین نسخه قبلی ممکن است نیازمند جستجو در بسیاری از نسخههای جایگزین باشد، زیرا مدلها به طور اجتنابناپذیری قدرت طراحی خود را کاهش میدهند. دلایل زیادی برای این تخریب وجود دارد، مانند تغییر در توزیع دادهها که می تواند منجر به کاهش سریع قدرت طراحی به عنوان جبران خطاها شود. تشخیص این کاهش ممکن است مستلزم مقایسه دادههای آموزشی با دادههای موثر، آموزش مجدد مدل، بررسی مجدد در مورد تصمیمات طراحی قبلی یا حتی طراحی مجدد مدل باشد.
درس گرفتن از اشتباهات
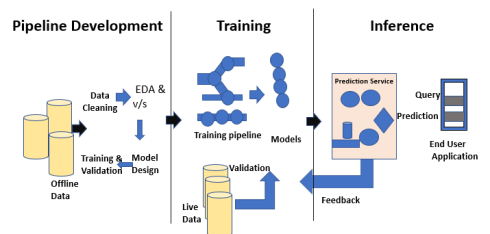
توسعه مدلها مستلزم آموزش و آزمایش مجموعه دادههای جداگانه است. استفاده بیش از حد از دادههای آزمایشی در طول تمرین میتواند باعث تعمیم و عملکرد ضعیف شود، زیرا ممکن است منجر به تناسب بیش از حد شود. زمینه در اینجا نقش حیاتی ایفا میکند، از این رو لازم است بفهمیم که از کدام دادهها برای آموزش مدلهای مورد نظر و با کدام پیکربندی استفاده شده است. چرخه زندگی یادگیری ماشینی مبتنی بر داده است زیرا مدل و خروجی آموزش به دادههایی که بر روی آن آموزش داده شده است مرتبط است. یک نمای کلی از پایان یافتن پایپلاین یادگیری ماشینی با یک نقطه نظر دادهای در شکل زیر نشانداده شدهاست :
مراحل مربوط به چرخه زندگی یادگیری ماشینی
برنامه نویس حوزه ی یادگیری ماشینی به طور مداوم با مجموعه دادههای جدید، مدلها، کتابخانههای نرمافزاری، پارامترهای تنظیم را به منظور بهینهسازی و افزایش دقت مدل آزمایش میکند. از این رو عملکرد مدل کاملاً به دادههای ورودی و فرآیند آموزش بستگی دارد.
-
ساخت مدل یادگیری ماشینی
این مرحله بر اساس برنامه نوع مدل را تعیین می کند. همچنین نشان میدهد که کاربرد مدل در مرحله یادگیری مدل طوری است که آنها را می توان مطابق با نیاز به یک کاربرد برنامه ی مورد نظر طراحی نمود. انواع مدلهای یادگیری ماشینی در دسترس هستند، مانند مدل نظارتی، مدل بدون نظارت، مدلهای طبقهبندی، مدلهای رگرسیون، مدلهای دستهبندی، و مدلهای یادگیری تقویتی.
-
آماده سازی دادهها
انواع دادهها را میتوان به عنوان ورودی برای اهداف یادگیری ماشینی استفاده کرد. این دادهها میتوانند از منابع متعددی مانند کسبوکار، شرکتهای دارویی، دستگاههای اینترنت اشیا، شرکتها، بانکها، بیمارستانها و غیره به دست آیند. حجم زیادی از دادهها در مرحله یادگیری ماشینی ارائه میشود، زیرا با افزایش تعداد دادهها، در جهت به دست آوردن نتیجه دلخواه تراز میشوند. این دادههای خروجی را میتوان برای تجزیه و تحلیل یا بهعنوان ورودی به سایر برنامهها یا سیستمهای یادگیری ماشینی که برای آنها بهعنوان یک جست و جو گر عمل میکند، استفاده کرد.
-
آموزش مدل
این مرحله مربوط به ایجاد یک مدل از دادههای داده شده است. در این مرحله، بخشی از دادههای آموزشی برای یافتن پارامترهای مدل مانند عاملهای مشترک چند جملهای یا معیارهایی در یادگیری ماشینی استفاده میشود که به حداقل رساندن خطا برای مجموعه دادههای داده شده کمک میکند. سپس از دادههای باقی مانده برای آزمایش مدل استفاده میشود. این دو مرحله به طور کلی چندین بار به منظور بهبود عملکرد مدل تکرار میشوند.
-
انتخاب پارامتر
این مورد شامل انتخاب پارامترهای مرتبط با آموزش است که به آن ابر پارامترها نیز گفته میشود. این پارامترها اثربخشی فرآیند آموزش را کنترل میکنند و از این رو، در نهایت عملکرد مدل به این بستگی دارد. آنها برای تولید موفق مدل یادگیری ماشینی بسیار مهم هستند.
-
یادگیری انتقال
از آنجایی که استفاده مجدد از مدلهای یادگیری ماشینی در حوزههای مختلف مزایای زیادی دارد، بنابراین، علیرغم اینکه نمیتوان یک مدل را مستقیماً بین حوزههای مختلف منتقل کرد، برای ارائه، از یک داده اولیه برای شروع آموزش مدل مرحله بعدی استفاده میشود. بنابراین زمان یادگیری را به میزان قابل توجهی کاهش میدهد.
6.تأیید مدل
ورودی این مرحله مدل آموزش دیده و توسط مرحله یادگیری مدل تولید شده و خروجی یک مدل تایید شده است که اطلاعات کافی را برای کاربران فراهم میکند تا تشخیص دهند که آیا مدل برای کاربرد مورد نظر خود مناسب است یا خیر. بنابراین، این مرحله از چرخه زندگی یادگیری ماشینی به این واقعیت مربوط میشود که یک مدل زمانی که با ورودیهایی که دیده نمیشوند به درستی کار کند.
-
مدل یادگیری ماشینی را مستقر کنید
در این مرحله ما از چرخه زندگی یادگیری ماشینی، برای ادغام مدلهای یادگیری ماشینی در فرآیندها و برنامهها استفاده میکنیم. هدف نهایی این مرحله، عملکرد مناسب مدل پس از استقرار است. مدلها باید به گونه ای مستقر شوند که بتوان از آنها برای نتیجه گیری استفاده کرد و همچنین باید به طور منظم به روز شوند.
-
نظارت
این شامل گنجاندن اقدامات ایمنی برای اطمینان از عملکرد صحیح مدل در عمر مفیدش است. برای تحقق این امر نیاز به مدیریت و به روز رسانی مناسب داریم.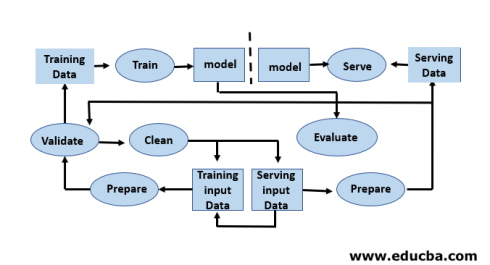
مزیت چرخه زندگی یادگیری ماشینی
یادگیری ماشینی مزایای قدرت، سرعت، کارایی و هوش را از طریق یادگیری بدون برنامهریزی صریح در یک برنامه کاربردی فراهم میکند. فرصتهایی را برای بهبود عملکرد، بهره وری و استحکام فراهم میکند.
نتیجه
سیستمهای یادگیری ماشینی روز به روز اهمیت بیشتری پیدا میکنند زیرا حجم دادههای درگیر در برنامههای مختلف به سرعت در حال افزایش است. فناوری یادگیری ماشینی قلب دستگاههای هوشمند، لوازم خانگی و خدمات آنلاین است. موفقیت یادگیری ماشینی را میتوان به سیستمهای حیاتی ایمنی، مدیریت دادهها، محاسبات با کارایی بالا که پتانسیل زیادی برای حوزههای کاربردی دارد، گسترش داد.
همچنین اخبار های علمی را بخوانید: