


دستهبندی نشده
پیش بینی پپتید ضد سرطان با ماشین لرنینگ و داکینگ مولکولی
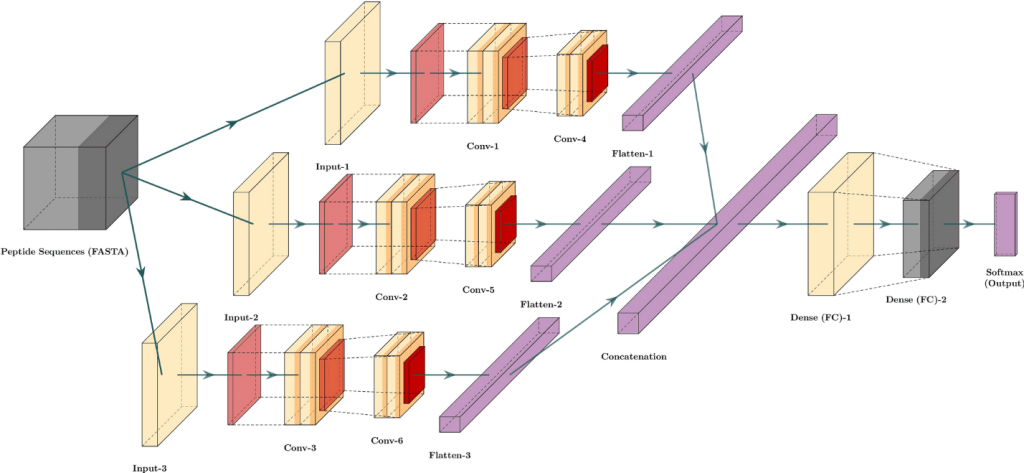
پیشبینی فعالیت پپتید ضد سرطان
سرطان یکی از علل اصلی مرگ و میر در سراسر جهان است. درمان مرسوم سرطان متکی به رادیوتراپی و شیمی درمانی است، اما هر دو روش عوارض جانبی شدیدی را برای بیماران به همراه دارند، زیرا این درمان ها نه تنها به سلول های سرطانی حمله می کنند، بلکه به سلول های طبیعی نیز آسیب می رسانند. پپتیدهای ضد سرطان (ACPs) یک جایگزین امیدوارکننده به عنوان عوامل درمانی هستند که در برابر سلول های تومور موثر و انتخابی هستند.
با وجود پیشرفت چشمگیر در مبارزه با سرطان در چند دهه گذشته، سرطان همچنان به عنوان یکی از علل اصلی مرگ و میر در جهان باقی مانده است. بر اساس آمار سازمان جهانی بهداشت (WHO)، یک ششم مرگ و میرهای گزارش شده ناشی از سرطان است که تخمین زده می شود ۹.۶ میلیون مرگ در سال ۲۰۱۸ داشته باشد. سرطان کولورکتال، سرطان معده، سرطان کبد و سرطان سینه و سایر سرطان های رایج تشخیص داده شده شامل سرطان پروستات و سرطان پوست نیز می باشد.
مکانیسم بیماریزای همه انواع سرطان ها تکثیر بینظم سلولهای سرطانی است که به صورت کنترل نشده رشد و تقسیم میشوند و حتی به بافتها و اندامهای طبیعی حمله میکنند. بنابراین هدف از درمان سرطان ممانعت از تکثیر سلول های سرطانی و جلوگیری از گسترش آنهاست. امروزه شیمی درمانی و رادیوتراپی راهبردهای اصلی درمان سرطان هستند.
با این حال، هر دو استراتژی مخرب هستند که ممکن است نه تنها سلول های سرطانی هدف را از بین ببرند، بلکه به سلول های سالم نیز آسیب می رساند و عوارض جانبی جدی در بیماران ایجاد می کند. بنابراین، توسعه یک درمان جایگزین که می تواند به طور خاص سلول های سرطانی را هدف قرار دهد، مهم است. یک راه حل امیدوارکننده، درمان سرطان مبتنی بر پپتید است. در مقایسه با درمان های سنتی، پپتید درمانی دارای چندین مزیت است که شامل ویژگی بالا، سمیت کم، توانایی نفوذ خوب به غشاء و تغییرات شیمیایی آسان است.
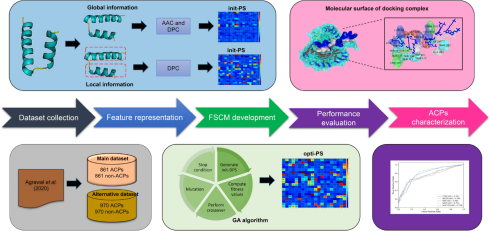
در سالهای اخیر، با توسعه شدید الگوریتمهای یادگیری ماشینی (ML)، روش های مبتنی بر ML بیشتر و بیشتر برای تسهیل کشف پپتیدهای ضد سرطانی (ACP) و داروها توسعه یافته اند. در این روشها، ویژگیها که توصیفگر نیز نامیده میشوند از توالیهای پپتیدی استخراج میشوند و برای آموزش مدلهای ML استفاده می شوند. به عنوان مثال، وو و همکاران PTPD را برای پیش بینی ACP ها با استفاده از روش رمزگذاری word2vec و شبکه عصبی پیشنهاد کرد.
وی و همکاران توانایی پیشبینی مدل را با استفاده از یک استراتژی بازنمایی ویژگی تطبیقی، یعنی استفاده از توصیفگرهای مختلف بسته به نوع پپتیدها، بهبود بخشیدند. گریسونی و همکاران یک مدل ML را برای کمک به طراحی و غربالگری ACPهای غشایی طراحی کرد. آنها از چهار شبکه عصبی ضد انتشار به خوبی آموزش دیده برای شناسایی پپتیدهایی که سلول های سرطان سینه و ریه را می کشند، استفاده کردند. علاوه بر این، لی و همکاران از ویژگیهای low-dimensional برای پیشبینی ACP استفاده کردند و عملکرد مدل آنها از برخی مدلهای موجود که از ویژگیهای با ابعاد بالا استفاده میکردند بهتر عمل کرد.
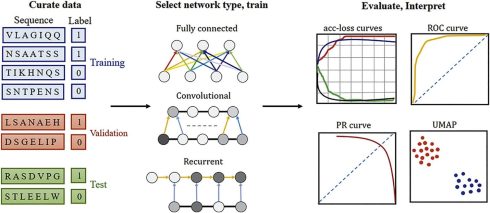
اکثر این روشهای پیشبینی ضد سرطان یا ضد باکتری برای انجام طبقهبندی پپتیدها بر اساس یک توالی اسید آمینه طراحی شدهاند. طبق دانش ما، تنها یک مطالعه وجود دارد که بر پیش بینی فعالیت بیولوژیکی پپتیدها متمرکز شده است. با این حال، این مطالعه وظیفه پیش بینی را به عنوان یک مشکل طبقه بندی چند طبقه ای در نظر گرفت که پپتیدها را به عنوان فعال، متوسط فعال یا غیر فعال طبقه بندی می کند.
بنابراین، روشهای جدیدی که میتوانند پیشبینی کمی فعالیت بیولوژیکی پپتیدهای خاص سرطان را فراهم کنند، هنوز مورد نیاز هستند. مانع اصلی در توسعه چنین روش هایی این است که داده های تجربی خاص سرطان محدود است. برای حل این مشکل، ما کاربرد یادگیری چندکاره (MTL) را برای پیشبینی فعالیت ضد سرطانی بررسی کردیم.
برخلاف یادگیری تک وظیفه ای (STL) که در آن چندین شبکه عصبی به طور مستقل برای وظایف مربوطه آموزش داده می شوند، MTL یک شبکه عصبی با لایه های مشترک را آموزش می دهد که به طور همزمان توسط چندین کار مرتبط به اشتراک گذاشته می شوند. با وجود عملکرد برتر، توضیح یا تفسیر مدلهای یادگیری عمیق دشوار است، زیرا روابط پیچیده بین ورودی و خروجی مرتبط با لایههای متعدد وجود دارد. چنین پیچیدگی درک این مدل ها در مورد چگونگی تصمیم گیری واقعی را دشوار می کند.
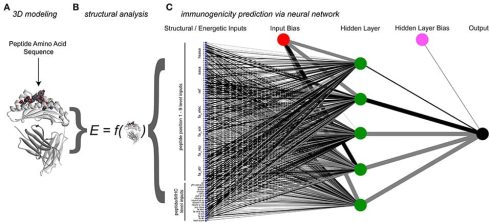
هدف از روش های ماشین لرنینگ یا یادگیری عمیق ارائه ی پیش بینی های خاص، قابل اعتماد و قابل تفسیر برای پیشبینی فعالیت ضد سرطانی پپتیدها می باشد. در روش های ماشین لرنینگ یک رویکرد سیستماتیک را برای ساخت و آزمایش مدلهای پیشبینی دنبال می کنند. ابتدا، از میان پنل توصیفگرهای توالی بررسی می کنند تا موارد مناسب را انتخاب نمایند که بتواند به طور موثر خصوصیات فیزیکوشیمیایی، تکاملی و اسمی توالیها را بدون از دست دادن اطلاعات موقعیت توالی رمزگذاری کنند.
سپس با استفاده از روش جستجوی شبکه ای، فراپارامترها را برای مدل های یادگیری تک وظیفه ای (STL) انتخاب می کنند. لازم به ذکر است که معماری مدل به طور ویژه برای یادگیری از مجموعه داده های ضد سرطانی کوچک تنظیم می شود. در نهایت، بهعنوان گامی به سمت یک مدل قابل تفسیر، به راههای مرتبط کردن نتایج پیشبینی با توالیهای ورودی نگاه می کنند، یعنی از مدل می پرسند که چرا نتیجه ی مورد نظر را پیشبینی میکند.
در اینجا، ما معتقدیم که یافتن تأثیرگذارترین توالی ها برای فعالیت بیولوژیکی پیشبینیشده، اولین سؤالی است که کاربران ممکن است بخواهند از مدل پیشبینی به آن پاسخ دهند.
محدودیت هایی در پیش بینی پپتیدهای ضد سرطان با ماشین لرنینگ وجود دارد. محدودیت اصلی حجم نمونه کوچک است. در حال حاضر، مجموعه دادههای open source مختلفی برای توسعه مدلهای پیشبینی پپتید ضد سرطانی مبتنی بر طبقهبندی وجود دارد. با این حال، از آنجایی که داده های سنجش بیولوژیکی برای توسعه مدل های پیش بینی فعالیت خاص سرطان مورد نیاز است، هنوز CancerPPD تنها پایگاه داده ای است که برای این منظور جامع است.
اگرچه MTL داده های موجود را که می تواند برای یادگیری استفاده شود گسترش داده است اما توالی های تکراری زیادی در انواع مختلف بافت وجود دارد، بنابراین فقط پیشرفت های محدودی می توان به دست آورد. از آنجایی که پپتیدهای ضد میکروبی و پپتیدهای ضد سرطان دارای خواص مشابهی مانند بار مثبت خالص، ترکیب آمفی پاتیک و مکانیسمهای عمل هستند، ترکیب توالیهای AMP در آموزش مدلهای ACP ممکن است تأثیر مثبتی بر عملکرد پیشبینی داشته باشد.
اخیرا تلاشهای فزایندهای برای بهبود پپتیدهای ضدسرطان مشتق شده طبیعی برای فعالیت بهتر به سمت سلولهای هدف با استراتژیهای مختلف مانند اصلاح نهایی، جایگزینی اسید آمینه، چرخهسازی، هیبریداسیون و اصلاح پلیمرها صورت گرفته است. بنابراین، پیشبینی فعالیت پپتیدهای اصلاحشده بهتر میتواند نیازهای فرآیند طراحی منطقی برای پپتیدهای ضد سرطانی مؤثر را برآورده کنند.
با شرکت در کارآموزی طراحی دارو ژنیران دانش خود را در مورد پیش بینی پپتید ضد سرطان با ماشین لرنینگ و داکینگ مولکولی افزایش دهید: