


دستهبندی نشده
مقدمهای بر سیستم یادگیری ماشینی

یادگیری عملی است که از طریق آن میتوان دانش ونحوه عملکرد را به دست آورد یا تغییر داد. زمانی که این دستور به کامپیوترها (ماشینها) منتقل میشود تا آنها بتوانند بدون اینکه به صراحت فرمان داده شوند, در انجام وظایف پیچیده به ما کمک کنند، یادگیری ماشینی متولد میشود. سیستمهای یادگیری ماشینی به عنوان زیرمجموعهای از هوش مصنوعی، الگوریتمها و آمار محاسباتی برای انجام طراحیهای قابل اعتمادی که در کاربردهای دنیای واقعی مورد نیاز است، استفاده میکند. یادگیری ماشینی برنامهای را با قابلیت خود ترمیمی ارائه میکند ولی بدون اینکه مجدد برنامهنویسی شود، یاد میگیرد چگونه ایرادات خود را رفع کند.
بر خلاف آموزش نرم افزار مرسوم که در آن قواعد پیش از تعریف، پیروی میشوند تا به یک راهحل دست یابند، سیستمهای یادگیری ماشینی با آزمایش روی رویکردهای مختلف به راهحل بهینه نزدیک میشوند.
سیستم یادگیری ماشینی چیست؟
هدف یادگیری ماشینی تعیین ارزش افزوده دقیق، از طریق یادگیری از الگوریتم آموزشدیده است. یک سیستم یادگیری ماشینی مجموعهای از فعالیتها از جمله جمعآوری دادهها تا استفاده از مدلی را که برای دورهی عمل مورد نظر خود ایجاد شده است، تشکیل میدهد.
این مقاله مروری بر مراحل مختلف درگیر در ساختن یک سیستم یادگیری ماشینی ارائه می دهد.
درک و تجزیه و تحلیل داده ها
وقتی علل و عوامل به وجود آمدن مشکل را بررسی کنیم، میتوانیم داده هایی را که به حل مشکل کمک میکنند را راحتتر پیدا کنیم.
علاوه بر این، میتوانیم یک طرح برای مجموعه مراحلی که قرار است برای رسیدن به راه حل بهینه برنامه ریزی شود، تنظیم کنیم.
یادگیری ماشینی داده محور
اگرچه در زمانهای اخیر ما به طور کلی دسترسی فراوانی به دادهها داریم، دستیابی به دادههای بدون خطایی که میتواند به یک طراحی موفق کمک کند، هنوز یک کار دشوار است. نزدیک به 80 درصد از زمان ایجاد برنامههای کاربردی یادگیری ماشینی صرف بحث و جدل دادهها و پیش پردازش دادهها می شود.
هنگام سر و کار داشتن با یادگیری ماشینی، بر خلاف انتظاراتی که وجود دارد، داده های بی نقصی ارائه نمیشوند. معمولاً با اطلاعات غیر ضروری یا نویز زیادی که در قالب یک فایل csv یا json ارائه میشود دادههای دقیقی نشان نمیدهد. قبل از اینکه بتوان از دادهها برای آموزش یک مدل یادگیری ماشینی استفاده کرد، باید اقدامات مناسبی انجام شود تا دادهها، آماده شوند. بسیاری از تکنیکهای آماری و تجسمی برای تصحیح دادهها و شکلدهی به مجموعه ویژگیها استفاده میشوند.
گامهای ابتدایی عبارت است از خلاصه کردن دادههای ارائه شده با انجام تجزیه و تحلیل دادههای اکتشافی برای پیدا کردن حقایق مربوط به:
- اطلاعات مربوط به داده ها : کمک به درک انواع دادههای مرتبط با هر ویژگی .
- شرح دادهها: برای کمک به مشاهده اینکه چه نوع داده ای در هر ویژگی وجود دارد.
- مقادیر از دست رفته: مقادیر از دست رفته اغلب مدل ماشین لرنینگ را برای دستیابی به پتانسیل کامل خود محدود میکند، از این رو پرداختن به آنها مهم می شود. آنها را میتوان بر اساس نیاز با 0 یا مقادیر میانگین، میانه (برای مقدار عددی) یا حالت (برای مقدار طبقه بندی) ویژگی خاص با مقادیر از دست رفته جایگزین کرد.
تجسم دادهها: گرافها و نمودارها برای نشان دادن رابطه بین ویژگیها استفاده میشود. برای مثال، یک نقشه حرارتی مناسب تصویری ترسیم شده میتواند به ما درک بهتری از همبستگی بین ویژگیها بدهد تا اینکه فقط به اعداد نگاه کنیم. تجزیه و تحلیل دادهها یک ایده برای فرموله کردن این که کدام رویکرد باید بیشتر استفاده شود را میدهد.
تصویری ترسیم شده از یک نقشه حرارتی مناسب
مهندسی ویژگی:
هنگامی که تجزیه و تحلیل اولیه انجام شد و ایدهای برای دادهها و مشکل پیش آمده داشتیم، میتوانیم برای ساخت لایه بعدی اقدام کنیم:
- انتخاب تنها ویژگیهای مربوطه: این را میتوان با روشهای کاهش ابعاد مانند ( PCA تحلیل مؤلفه اصلی)، تحلیل عاملی، (LDA تحلیل متمایز خطی) به دست آورد.
- دور انداختن نویز و نقاط پرت در داده ها: این را میتوان با اجرای روشهایی مانند منظم سازی، اعتبارسنجی k-fold، در نظر گرفتن مقادیر در منطقه IQR یا حتی حذف ویژگیهای اضافی به دست آورد.
مدلسازی سیستم یادگیری ماشینی:
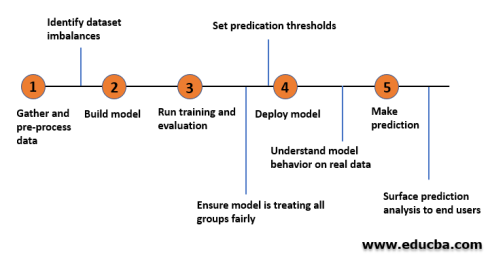
- انتخاب مدل
انتخاب مدل، فرآیند انتخاب الگوریتمی است که به بهترین وجه با الزامات یک بیان مسئله معین مطابقت دارد. به عنوان یک قاعده کلی، الگوریتمهای رگرسیون برای پیشبینی مقادیر پیوسته ترجیح داده میشوند، در حالی که الگوریتمهای طبقهبندی زمانی استفاده میشوند که هدف دارای دستههای باینری یا چندگانه باشد.
- آموزش و ارزیابی مدل
دادههای به دست آمده برای آموزش مدل را میتوان به 3 مجموعه تقسیم کرد، یعنی مجموعه آموزشی، مجموعه اعتبار سنجی و مجموعه تست. به طور کلی، 70٪ از دادهها برای آموزش استفاده میشود و 30٪ باقی مانده برای اعتبار سنجی آموزش مدل قبل از استفاده بر روی دادههای آزمون مجهول استفاده میشود.
هنگامی که یک مدل انتخاب میشود، باید روی دادههای از پیش پردازش شده با تنظیم فراپارامترهای مورد نیاز برای دستیابی به عملکرد خوب و جلوگیری از پردازش بیش از حد آموزش داده شود. یک مدل یادگیری ماشینی خوب نه تنها بر روی دادههای آموزشی، بلکه بر روی دادههای آزمایشی امتحان نشده نیز به طور استثنایی جواب میدهد. از این رو ارزیابی مدل آموزش دیده بر روی جنبههای کلیدی به عنوان یک گام حیاتی قبل از پیش بینی مقادیر هدف میباشد. نتایج بهدستآمده برای ارسال ارزیابی اولیه میتواند برای تحلیل بیشتر و تنظیم دقیق مدل استفاده شود.
3.جاگذاری مدل
جاگذاری مدل مرحلهای است که در آن یک مدل یادگیری ماشینی فعال که برای پارامترهای مختلف آزمایش شده است برای خدمات خود در دنیای واقعی در دسترس قرار میگیرد. مدلهای آماده تولید با استفاده از پایپلاین ایجاد میشوند که تمام مراحل از جمعآوری دادهها تا پیشپردازش دادهها تا آموزش مدل را در بر میگیرد که از یک دوره CI/CD مناسب را تضمین میدهد. سیستم ماشین لرنینگ در صورتی که بتواند برای ثبات و تکرارپذیری در مراحل آزمایش بعدی مورد استفاده قرار گیرد سودمند خواهد بود .
- به دنبال به روز رسانیها باشید
پس از جا گذاری موفق سیستم ماشین لرنینگ ، کار تمام نمیشود. حتی پس از انتخاب و جاگذاری یک مدل، نیاز دائمی به روز رسانی منظم سیستم وجود خواهد داشت. سیستمهای یادگیری ماشینی در طول زمان از بین میروند. با جمع آوری دادههای جدید یک روز در میان، نیاز به بررسی سیستم یادگیری ماشینی و به روز رسانی آن برای مطابقت با الزامات جدید اجباری است.
تجزیه و تحلیل خطا در سیستم یادگیری ماشینی
یک رویکرد خوب و توصیهشده در طراحی سیستم ML، دور نگه داشتن پیچیدگیها است. لزومی ندارد که یک سیستم ML خوب با یک الگوریتم و رویکرد پیچیده پشتیبانی شود. اگر یک الگوریتم ساده بتواند الزامات بیان مسئله را برآورده کند، احتمالاً استفاده از آن حداقل برای شروع بهترین گزینه خواهد بود.
برخورد با خطاها و بهینه سازی سیستم ML می تواند توسط:
- اجرای تکنیک هایی مانند اعتبار سنجی متقابل، برای دستیابی به بهبود.
- با تجسم نقاط داده و بر اساس تحلیلهایی مانند سوگیری و واریانس، میتوان تصمیم گرفت که آیا داده های بیشتر، ویژگیهای بیشتر و غیره را شامل شود.
- با اجتناب از بهینه سازی زودرس، بسیار ضروری است که به جای همراهی با احساس درونی، اجازه دهید شواهد شما را راهنمایی کنند.
نتیجه – سیستم یادگیری ماشینی
بر خلاف تصور مرسوم، ساختن یک سیستم ML موفق تنها به انتخاب مدلی برای آموزش و اعتبار بستگی ندارد. دادههای با کیفیت باید انتخاب، تجزیه و تحلیل و از قبل پردازش شوند تا پایه ای قوی برای یک سیستم ML با کار طولانی مدت ایجاد شود. هر مسیری که برای رسیدن به مقصد در ساختن یک سیستم ML طی میشود، باید کاملاً بر اساس حقایق بهدستآمده در طول تجزیه و تحلیل دادهها باشد تا شهود یا احساس درونی.
همچنین اخبار های علمی را بخوانید: