


دستهبندی نشده
مقدمهای بر تکنیکهای یادگیری ماشین
تکنیکهای یادگیری ماشین (مانند رگرسیون, طبقهبندی, دستهبندی, تشخیص ناهنجاری, و غیره) برای ساختن دادههای آموزشی یا یک مدل ریاضی با استفاده از الگوریتمهای خاص مبتنی بر محاسبات برای پیشبینی بدون نیاز به برنامهنویسی استفاده میشوند، چرا که این تکنیکها به دلیل پیشبینی مشکلات سیستم، اتوماسیون کارها را با کاهش هزینه و نیروی انسانی، مدلسازی و ترویج میکند.
تکنیکهای یادگیری ماشین
چندین روش وجود دارند که در ترویج این سیستمها برای یادگیری به طور خودکار و بهتر شدن تجربیات تأثیرگذار هستند. اما آنها تحت دستهها یا انواع مختلف یادگیری ماشین مانند یادگیری نظارتی، یادگیری بدون نظارت، یادگیری تقویتی، یادگیری عمیق و غیره قرار میگیرند.
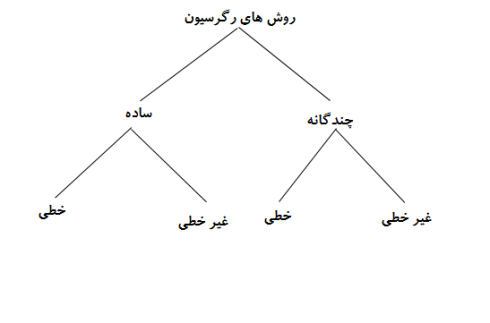
- رگرسیون
الگوریتمهای رگرسیون بیشتر برای پیشبینی اعداد استفاده میشوند، یعنی زمانی که خروجی یک مقدار واقعی یا پیوسته است. از آنجایی که تحت آموزش نظارتی قرار میگیرد، با دادههای آموزش دیده برای پیشبینی دادههای آزمایشی جدید کار میکند. به عنوان مثال، سن میتواند یک مقدار پیوسته باشد زیرا با گذشت زمان افزایش مییابد. چند مدل رگرسیون وجود دارد که در زیر نشان داده شده است:
برخی از الگوریتمهای پرکاربرد در تکنیکهای رگرسیون
- مدل رگرسیون خطی ساده: روشی آماری است که رابطه بین دو متغیر کمی را تحلیل میکند. این تکنیک بیشتر در زمینههای مالی، املاک و غیره کاربرد دارد.
- رگرسیون لسو: عملگر گزینش و انقباض کمترین قدرمطلق یا LASSO زمانی استفاده میشود که نیاز به زیرمجموعهای از پیش بینیکننده برای به حداقل رساندن خطای پیشبینی شده در یک متغیر پیوسته داشته باشیم.
- رگرسیون لجستیک: در موارد کشف تقلب، آزمایشات بالینی و غیره هر جا که خروجی باینری (binary) باشد استفاده میشود.
- رگرسیون بردار پشتیبانی: SVR کمی با SVM متفاوت است. در رگرسیون ساده، هدف به حداقل رساندن خطا است، در حالی که در SVR، ما میزان خطا را محدود میکنیم.
- الگوریتم رگرسیون چند متغیره: این تکنیک در مورد متغیرهای پیش بینیکننده چندگانه استفاده میشود. میتوان آن را با عملیات ماتریس و کتابخانه Numpy پایتون اجرا کرد.
- الگوریتم رگرسیون چندگانه: با چندین متغیر کمی در الگوریتم های رگرسیون خطی و غیرخطی کار میکند.
- طبقه بندی
روش طبقهبندی، روشی برای یادگیری نظارتی، از مقادیر مشاهده شده به طور یک یا چند نتیجه به صورت طبقهبندی نتیجهگیری میکند. به عنوان مثال، ایمیل دارای فیلترهایی مانند صندوق ورودی، پیشنویس، اسپم و غیره است. تعدادی الگوریتم در مدل طبقهبندی مانند رگرسیون لجستیک، درخت تصمیم، جنگل تصادفی، برداشت چند لایه و غیره وجود دارد. در این مدل، دادههای خود را به طور خاص طبقهبندی می کنیم و برچسبها را بر این اساس به آن دستهها اختصاص میدهیم. طبقهبندی کنندهها دو نوع هستند:
- طبقهبندی کنندههای باینری: طبقهبندی با 2 دسته مجزا و 2 خروجی.
- طبقهبندی کنندههای چند دستهای: طبقه بندی با بیش از 2 دسته.
- خوشهبندی
خوشهبندی یک تکنیک یادگیری ماشین است که شامل طبقهبندی نقاط داده در گروه های خاص میباشد. اگر تعدادی کد مقصود یا نقاط داده داریم، میتوانیم الگوریتم(های) خوشهبندی را برای تجزیه و تحلیل و گروهبندی آنها بر اساس ویژگیها و داده ها اعمال کنیم. این روش از تکنیک بدون نظارت به دلیل تکنیکهای آماری آن استفاده می شود. الگوریتمهای خوشهای بر اساس دادههای آموزشی پیشبینی می کنند و بر اساس شباهت یا آشنا نبودن خوشههایی را ایجاد میکنند.
روشهای خوشه بندی:
- روش مبتنی بر چگالی: در این روش، خوشهها بسته به شباهت و تفاوت آنها با ناحیه کم چگال یا مناطق چگال در نظر گرفته میشوند.
- روش سلسله مراتبی: خوشههای تشکیل شده در این روش ساختارهای درخت مانند هستند. این روش درختان یا خوشههایی را از خوشه قبلی تشکیل میدهد. دو نوع روش سلسله مراتبی وجود دارد: ترکیبی (رویکرد پایین به بالا) و تقسیمی (رویکرد از بالا به پایین).
- روش تقسیمبندی: این روش اشیاء را بر اساس k-cluster تقسیم بندی میکند و هر دسته یک خوشه واحد را تشکیل میدهد.
- روشهای مبتنی بر Gris: در این روش دادهها در تعدادی سلول ترکیب میشوند که ساختار شبکهای را تشکیل میدهند.
- تشخیص ناهنجاری
تشخیص ناهنجاری، فرآیند شناسایی موارد یا رویدادهای غیرمنتظره در یک مجموعه داده است. برخی از زمینههایی که از این تکنیک استفاده میشود عبارتند از تشخیص تقلب،عیب یابی، نظارت بر سلامت سیستم و غیره.
تشخیص ناهنجاری را میتوان به طور کلی به صورتهای زیر دستهبندی کرد:
- ناهنجاریهای نقطهای: ناهنجاریهای نقطهای زمانی تعریف میشوند که داده، واحد غیرمنتظره باشد.
- ناهنجاریهای زمینهای: وقتی ناهنجاریها مختص زمینهی خاصی هستند، به آن ناهنجاریهای زمینهای میگویند.
- ناهنجاریهای جمعی: هنگامی که مجموعه یا گروهی از اقلام داده مرتبط غیرعادی هستند، آن را ناهنجاری جمعی می نامند.
تکنیکهای خاصی در تشخیص ناهنجاری به شرح زیر وجود دارد:
- روشهای آماری: با اشاره به دادههایی که از روشهای آماری مانند میانگین، میانه، مد و غیره منحرف میشوند، به شناسایی ناهنجاریها کمک میکند.
- تشخیص ناهنجاری مبتنی بر چگالی: بر اساس الگوریتم k نزدیکترین همسایه است.
- الگوریتم ناهنجاری مبتنی بر خوشه: نقاط داده زمانی که تحت یک گروه قرار میگیرند به صورت یک خوشه جمع آوری و از مرکزهای محلی تعیین میشوند.
- ماشین بردار پشتیبانی: الگوریتم، به خود آموزش میدهد تا نمونه های داده معمولی را خوشه بندی کند و با استفاده از دادههای آموزشی ناهنجاریها را شناسایی کند.
کار بر روی تکنیک های یادگیری ماشین
یادگیری ماشین از الگوریتمهای زیادی برای مدیریت و کار با مجموعه دادههای بزرگ و پیچیده برای پیشبینی بر اساس نیاز استفاده میکند.مثلا تصویر اتوبوس را در گوگل جستجو میکنیم. بنابراین، گوگل اساساً تعدادی نمونه یا مجموعه داده با برچسب اتوبوس دریافت میکند و سیستم الگوهای پیکسلها و رنگها را پیدا میکند که به یافتن تصاویر صحیح از اتوبوس کمک میکند.
سیستم گوگل با کمک الگوها یک حدس تصادفی از اتوبوس مانند تصاویر ایجاد میکند. اگر اشتباهی رخ دهد، خود را برای دقت بیشتر تنظیم میکند. در پایان، این الگوها توسط یک سیستم کامپیوتری بزرگ مدلسازی شده مانند مغز انسان یا شبکه عصبی عمیق برای شناسایی نتایج دقیق از تصاویر، آموزش داده میشوند. این روشی است که تکنیکهای ML برای گرفتن بهترین نتیجه همیشه استفاده میکنند.
نتیجه
یادگیری ماشین کاربردهای مختلفی در زندگی واقعی دارد تا به ساختمانهای تجاری، افراد و غیره کمک کند که به نتایج خاصی بر حسب نیاز دست یابند. برای به دست آوردن بهترین نتایج، تکنیکهای خاصی مهم هستند که در بالا مورد بحث قرار گرفته اند. این تکنیکهای مدرن، آیندهنگر هستند و اتوماسیون کارها را با نیروی انسانی و هزینه کمتر ترویج میکنند.