


دستهبندی نشده
انواع الگوریتم های یادگیری ماشین

مقدمه ای بر انواع الگوریتمهای یادگیری ماشین
الگوریتم های یادگیری ماشین یا محاسبات هوش مصنوعی برنامههایی (ریاضی و منطقی) هستند که برای ارائه اطلاعات بیشتر، خود را برای عملکرد بهتر اصلاح میکنند. «تطبیق» بخشی هوش مصنوعی به این معناست که این پروژهها نحوه پردازش اطلاعات را پس از مدتی تغییر میدهند، همانطور که مردم نحوه پردازش اطلاعات را با یادگیری تغییر میدهند. بنابراین، یادگیری ماشینی یا محاسبه هوش مصنوعی، برنامهای است که با توجه به نقد و بررسی انتظارات از خروجیهای ساخته شده از مجموعه دادهها، با روشی خاص پارامترهای خاص خود را تغییر میدهد.
انواع الگوریتمهای یادگیری ماشین
معمولاً میتوان این الگوریتمها را بر اساس محرک خود به کلاسهایی تقسیم کرد که این طبقهبندیهای اساسی به شرح ذیل است:
- یادگیری تحت نظارت
- یادگیری بدون نظارت
- یادگیری نیمه نظارتی
- یادگیری تقویتی
یادگیری تحت نظارت چیست؟
یادگیری تحت نظارت همانند به کارگیری یک مربی است که یادگیری را هدایت میکند. ما یک مجموعه داده داریم که به عنوان یک آموزشدهنده کار میکند و کار آن آماده کردن مدل یا ماشین است. وقتی که مدل آماده شد، با ارائه اطلاعات جدید، مدل میتواند شروع به پردازش برای رسیدن به یک انتظار یا انتخاب کند.
نمونه هایی از یادگیری تحت نظارت:
- شما عکسهای زیادی با دادههایی در مورد آنچه درون آنها است دریافت میکنید و پس از آن، یک مدل را برای درک عکسهای جدید آموزش میدهید.
- شما اطلاعات زیادی در مورد قیمت خانهها بر اساس اندازه و مکان آنها دارید و آن را به مدل وارد میکنید و آن را آموزش میدهید، سپس میتوانید قیمت خانههای دیگر را بر اساس دادههایی که به مدل وارد کردهاید، پیش بینی کنید.
- اگر میخواهید پیشبینی کنید که پیام شما هرزنامه است یا خیر، میتوانید بر اساس پیامهای قدیمیتری که دارید، پیشبینی کنید که پیام جدید هرزنامه است یا خیر.
الگوریتمهای یادگیری تحت نظارت به شرح زیر است:
- رگرسیون خطی
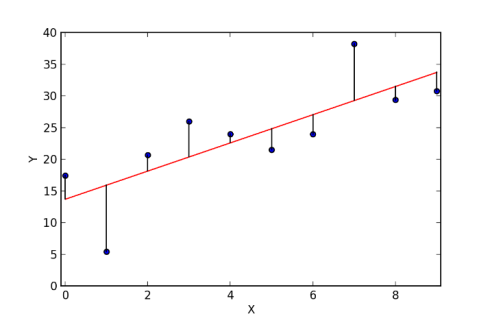
رگرسیون خطی برای کشف ارتباط بین دو عامل پایدار ارزشمند است. یکی یک متغیر پیشبینی کننده یا مستقل است و دیگری یک متغیر واکنشی یا بخشی. رگرسیون خطی به دنبال روابط قابل اندازهگیری است، اما نه یک رابطه قطعی. گفته میشود که ارتباط بین دو عامل قطعی است در صورتی که یک متغیر بتواند با متغیر دیگر به طور دقیق تبادل اطلاعات داشته باشد. به عنوان مثال، با استفاده از دما بر حسب درجه سانتیگراد، میتوان به طور دقیق دما را بر حسب فارنهایت پیش بینی کرد. یک رابطه عملی در تصمیم گیری برای ارتباط بین دو عامل دقیق نیست. به عنوان مثال، رابطه در محدوده ارتفاع و وزن. ایده مرکزی این روش رسیدن به خطی است که به بهترین وجه بر روی اطلاعات برازش میشود. بهترین خط برازش خطی است که خطای پیشبینی همه جانبه برای آن (تمام تمرکز اطلاعات) به همان اندازه که مورد انتظار است، کم باشد. خطا برابر فاصله بین آن نقطه از خط رگرسیون است.
- درختان تصمیم
درخت تصمیم یک ابزار کمکی تصمیمگیری است که از نمودار یا مدل درخت مانندی از تصمیمات و نتایج بالقوه آنها، از جمله نتایج رویدادهای تصادفی، هزینههای منابع و ابزار استفاده میکند.
- طبقه بندی بیز ساده (Naive Bayes Classification)
طبقهبندی بیز ساده گروهی از طبقهبندیکنندههای احتمالی پایه است که وابسته به بکارگیری نظریه بیز (Bayes’ theory) با خود نظارتی قوی (غیر پیچیده) ویژگیهای بیز ساده است. نمونههایی از کاربرد این طبقه بندی در مدلهای قابل تایید عبارتند از:
- برای مهر زدن ایمیل به عنوان هرزنامه بودن یا نبودن.
- مرتب سازی یک خبر بر اساس موضوع (نوآوری، مسائل دولتی یا ورزش و …)
- بررسی لمس مادهای که احساسات مثبت یا احساسات منفی را منتقل میکند.
- استفاده در برنامه نویسی تصدیق چهره.
- رگرسیون لجستیک (Logistic Regression)
رگرسیون لجستیک یک روش واقعی پیشگامانه برای نشان دادن یک عبارت دو جملهای با حداقل یک عامل اطلاعاتی است. این روش ارتباط بین متغیر بخشی مطلق و حداقل یک عامل آزاد را به وسیله ارزیابی احتمالات با استفاده از یک ظرفیت لجستیک و تخصیص ترکیبی لجستیک، کمّی میکند.
به طور معمول، رگرسیونها در زندگی واقعی قابل استفاده هستند مانند:
- بررسی امتیاز اعتباری
- اندازهگیری میزان موفقیت بازار یا شرکت
- برای پیشبینی درآمد هر شرکت یا هر محصول
- آیا هر روز زلزله ای رخ میدهد؟
- رگرسیون حداقل مربعات معمولی (Ordinary Least Squares Regression)
حداقل مربعات یک استراتژی برای اجرای رگرسیون مستقیم است. رگرسیون مستقیم عبارت است از برازش یک خط از طریق تمرکزهای زیاد. روشهای بالقوه مختلفی برای انجام این کار وجود دارد و سیستم «کمترین مربعات معمولی» به این صورت است:
میتوانید یک خط بکشید، و پس از آن، برای همه مراکز داده، فاصله عمودی بین نقطه و خط را اندازهگیری کنید. آنها را ادغام کنید. خط برازش مکانی خواهد بود که این مجموع فواصل با توجه به وضعیت فعلی، به همان اندازه که میتواند نرمال باشد، ناچیز است.
یادگیری بدون نظارت چیست؟
در این رویکرد، مدل از طریق ادراک یاد میگیرد و ساختارهایی را در اطلاعات کشف میکند. هنگامی که به مدل یک مجموعه داده داده میشود، به وسیله ایجاد دستههایی در آن، نمونهها و ارتباطات را در مجموعه دادهها کشف میکند. مدل نمیتواند علامتی به دسته اضافه کند. برای مثال یک ظرف حاوی تعدادی سیب و انبه در نظر بگیرید. این رویکرد نمیتواند این حالت را مجموعه سیب یا انبه بیان کند. با این حال میتواند هر یک از سیبها را از انبهها جدا کند.
فرض کنید ما تصاویری از سیب، موز و انبه را به مدل نمایش میدهیم. سپس مدل مجموعه دادهها را خوشهبندی کرده و با توجه به نمونهها و ارتباطات خاص آن، مجموعه دادهها را به آن گروهها تقسیم میکند. اگر با اطلاعات دیگری مدل تقویت شود، آن اطلاعات را به یکی از دستههای ساخته شده اضافه میکند.
نمونههایی از یادگیری بدون نظارت
- شما تعداد زیادی عکس از 6 فرد دارید، اما اطلاعاتی در مورد اینکه هر یک در کدام عکسها قرار دارند، ندارید. باید این مجموعه داده را در 6 پشته، هر کدام با عکسهای یک نفر، جدا کنید.
- شما ذراتی دارید که بخشی از آنها دارو هستند و قسمتهایی نه. با این حال نمیدانید که کدام ذره دارو است یا نه و برای یافتن داروها به محاسبه نیاز داری
الگوریتمهای یادگیری بدون نظارت به شرح زیر است:
خوشه بندی
مهمترین ایده الگوریتم خوشهبندی، در نظر گرفتن یادگیری بدون کمک است. در بیشتر موارد، ساختار یا نمونهای را در جمع آوری اطلاعات دستهبندی نشده پیدا میکند. محاسبات خوشهبندی، اطلاعات شما را پردازش میکند و در صورت وجود در اطلاعات، خوشهها (گروههای) خاص را کشف میکند. همچنین میتوانید تعداد دستههایی را که باید محاسبات شما متمایز کند، تغییر دهید. این امر شما را قادر میسازد تا تقسیمبندیهای این جمعها را تغییر دهید.
در زیر انواع مختلفی از خوشهبندی که میتوانید از آنها استفاده کنید، آورده شده است:
- انتخابی (تقسیم بندی)
- مدل K-means
- تجمعی
- مدل خوشهبندی سلسله مراتبی
- پوشش
- مدل Fuzzy C-Means
- احتمالی
انواع الگوریتمهای خوشهبندی
- خوشه بندی سلسله مراتبی (Hierarchical Clustering)
- K-means Clustering
- K-NN (نزدیکترین همسایه k (k nearest neighbors))
- آنالیز مؤلفههای اصلی (Principal Component Analysis)
- تجزیه مقادیر منفرد (Solitary Value Decomposition)
- تحلیل مولفههای مستقل (Independent Component Analysis)
خوشه بندی سلسله مراتبی
خوشهبندی سلسله مراتبی محاسبهای است که سلسله مراتب گروهها را میسازد. این الگوریتم با هر یک از اطلاعاتی که به دسته خاص خود نسبت داده شده، شروع میکند. در اینجا، دو گروه نزدیک در یک دسته مشابه قرار خواهند گرفت. این محاسبه زمانی تمام میشود که فقط یک گروه باقی بماند.
K-means Clustering
این الگوریتم یک محاسبه خوشهبندی تکراری است که شما را تشویق میکند تا مهمترین محرک را برای هر تکرار پیدا کنید. در ابتدا تعداد ایدهآل گروهها انتخاب میشود. در این تکنیک خوشهبندی، شما باید اطلاعاتی را که بر روی تعداد k جمع متمرکز است، دستهبندی کنید. یک k بزرگتر به معنای جمع کوچکتر با تقسیمبندی بیشتر است. به طور مشابه k کوچکتر به معنای جمع بزرگتر با تقسیمبندی کمتر است.
نتیجه این محاسبه مجموعهای از “نامها” است. این امر اجازه میدهد تا اطلاعات به یکی از k جمع اشاره کند. در خوشهبندی k-means، هر جمع با ساختن یک مرکز برای خودش مشخص میشود. مرکزها مانند هسته دستهها هستند که نزدیکترین کانونها را به خود جلب میکنند و آنها را به گروه اضافه میکنند.
الگوریتم خوشهبندی K-mean دارای دو زیر گروه که در ادامه آورده شده است، میباشد:
- خوشهبندی تجمعی (Agglomerative clustering)
- دندروگرام (Dendrogram)
- خوشه بندی تجمعی
این نوع از روش خوشهبندی K-means با تعداد ثابتی از دستهها آغاز میشود. سپس تمام اطلاعات را در تعداد دقیقی از گروهها معین میکند. این استراتژی خوشهبندی به تعداد گروههای K به عنوان اطلاعات نیاز ندارد. روند تراکم با شکل دادن به هر داده به عنوان یک دسته منفرد آغاز میشود.
این استراتژی از برخی تکنیکهای جداسازی استفاده میکند، تعداد دستهها (یکی در هر تکرار) را با ترکیب فرآیندها کاهش میدهد. در پایان، ما یک گروه بزرگ داریم که شامل هر یک از موجودیتها است.
- دندروگرام
در تکنیک خوشهبندی دندروگرام، هر سطح از یک دسته امکان پذیر صحبت میکند. ارتفاع دندروگرام درجه تشابه بین دو دسته ادغام شده را نشان میدهد. یافته دندروگرام دستهای است که به تدریج قابل مقایسه بوده که مشخصه نیست و در بیشتر موارد انتزاعی است.
الگوریتم K-Nearest neighbors
این الگوریتم سرراستترین طبقهبندی کننده هوش مصنوعی است. با این حال، از این نظر که مدلی را ارائه نمیدهد، با سایر روشهای هوش مصنوعی متفاوت است. در عوض یک محاسبه ساده است که تک تک موارد قابل دسترس را ذخیره میکند و نمونههای جدید را بسته به اندازه تشابه، مشخص میکند.
این روش زمانی که مدلها از هم تفکیک شدهاند، بسیار خوب کار میکند. با این حال زمانی که مجموعه دادهها جهت آمادهسازی مدل، بسیار بزرگ است و عدد جداسازی کم نیست، نرخ یادگیری متوسط است.
الگوریتم آنالیز مؤلفههای اصلی
یک مجموعه با بُعد پایین از ویژگیها را از یک مجموعه دارای بُعد بالا استخراج میکند. یعنی به فضایی با ابعاد بالاتر نیاز دارید. شما باید یک زیر مجموعه از پیشبینها که حاوی بیشترین اطلاعات درباره دادهها هستند برای آن فضا و فقط 200 امتیاز مهم آن فرض را انتخاب کنید. این امر به عنوان یک جزء اصلی این روش شناخته میشود. زیرمجموعهای که انتخاب میکنید شامل فضای دیگری است که از نظر اندازه کوچک و یک فضای منحصر به فرد میباشد. با این حال بیشتر ماهیت چند وجهی اطلاعات را همانطور که میتوان انتظار داشت، حفظ میکند.
یادگیری تقویتی چیست؟
یادگیری تقویتی ظرفیت یک متخصص برای تعامل با محیط و کشف بهترین نتیجه است و ایده ضربه و تکنیک مقدماتی را دنبال میکند. اپراتور با یک امتیاز برای یک پاسخ درست یا غلط پاداش میگیرد یا مجازات میشود، و بر اساس تمرکز بر پاداش مثبت، مدل خودش را آموزش میدهد. مدل پس از آماده شدن، میتواند اطلاعات جدیدی را که به آن معرفی شده است، پیش بینی کند.
نمونههای از یادگیری تقویتی
- نمایش تبلیغات، با توجه به علایق کاربر، برای مدت طولانی بهینه سازی میشود.
- محاسبه بودجه تبلیغات مورد استفاده در زمان واقعی.
- یادگیری تقویتی معکوس برای شناخت بهتر علایق مشتریان.
یادگیری نیمه نظارتی چیست؟
نوعی از یادگیری است که محاسبه بر روی ترکیبی از اطلاعات نامگذاری شده و بدون برچسب انجام میشود. به طور معمول، این ترکیب حاوی مقدار محدودی از اطلاعات نامگذاری شده و تعداد زیادی اطلاعات بدون برچسب است. اساس روش مذکور شامل این است که مهندس نرمافزار ابتدا اطلاعات قابل مقایسه را با استفاده از یک روش یادگیری بدون کمک، گروهبندی میکند و سپس از اطلاعات نامگذاری شده فعلی برای نامگذاری بقیه اطلاعات بدون برچسب استفاده میکند. نمونههای استفاده معمولی از این نوع محاسبات دارای یک ویژگی مشترک هستند:
به دست آوردن اطلاعات بدون برچسب عموماً ساده است در حالی که نام گذاری اطلاعات مذکور بیش از حد گران است.
به طور طبیعی، میتوان سه نوع محاسبه یادگیری را بهعنوان تحتنظارت در نظر گرفت:
- جایی که یک دانشآموز تحت نظارت معلم در خانه و مدرسه است
- بدون نظارتی جایی که فرد دانشآموز کجا باید خودش ایدهای را بفهمد.
- نیمهنظارتی جایی که مربی چند ایده را در کلاس نشان میدهد و سوالاتی را به عنوان تکالیف مدرسه ارائه میدهد که به ایدههای مشابه بستگی دارد.
نمونه هایی از یادگیری نیمه نظارتی
جالب است که اطلاعات بیشتر مساوی است با مدلهای با کیفیت بهتر در یادگیری عمیق (نسبت به یک نقطه خاص از محدوده اطلاعات، با این حال ما اغلب اطلاعات زیادی در اختیار نداریم). هر چند که ممکن است، دریافت اطلاعات مشخص شده پرهزینه باشد.
به عنوان مثال، اگر نیاز به تهیه مدلی برای تشخیص حیوانات بالدار دارید، میتوانید دوربینهای زیادی را برای عکس گرفتن از پرندگان تنظیم کنید، که به طور کلی امری ساده است. اما قرارداد با افراد برای علامتگذاری آن عکسها هزینهبر است. این احتمال را در نظر بگیرید که تعداد زیادی عکس از حیوانات بالدار دارید.
با این حال، فقط به این افراد بگویید تا زیر مجموعه کوچکی از عکسها را علامت گذاری کنند. همانطور که مشخص شد، به جای آموزش ساده مدلها با زیر مجموعههای علامتگذاری شده، میتوانید مدل را روی کل مجموعه آموزشی قبل از بهبود آن با زیرمجموعههای نامگذاری شده، آموزش دهید و نشانههایی از بهبود عملکرد در طول این روند را مشاهده کنید. این یعنی یادگیری نیمه نظارتی که در هزینههای شما صرفه جویی میکند.
نتیجه گیری
انواع مختلفی از الگوریتمهای یادگیری ماشین وجود دارند و بر اساس شرایط مختلف، ما باید از بهترین الگوریتم برای رسیدن به بهترین نتیجه استفاده کنیم. الگوریتمهای زیادی در هر روش یادگیری ماشین وجود دارند که با بهترین دقت خروجی را پیدا میکنند، و این بیشترین دقتی است که ما برای استفاده از آن الگوریتمها داریم. ما میتوانیم خطای هر الگوریتم را با کاهش نویز در دادهها به حداقل برسانیم. در نهایت، میتوان گفت که هیچ الگوریتم یادگیری ماشین وجود ندارد که بتواند دقت 100 درصدی را به شما بدهد. حتی مغز انسان هم نمیتواند این کار را انجام دهد، بنابراین بهترین الگوریتم را برای کار بر روی دادههای خود پیدا کنید.
مترجم: فاطمه فریادرس
همچنین اخبار های علمی را بخوانید:
منظور از تئوری اطلاعات در درخت یادگیری چیست؟
تئوری اطلاعات در درخت یادگیری یعنی استفاده از مفاهیمی مانند آنتروپی (Entropy) و کسب اطلاعات (Information Gain) برای تصمیمگیری در تقسیم دادهها.
🔹 آنتروپی: میزان بینظمی یا عدم قطعیت دادهها
🔹 Information Gain: کاهش آنتروپی پس از تقسیم داده با یک ویژگی
✅ الگوریتم درخت یادگیری (مثل ID3 یا C4.5) ویژگیای را انتخاب میکند که بیشترین Information Gain را داشته باشد تا بهترین جداسازی را انجام دهد.
دوره یادگیری تقویتی دارید
با سلام، از دوره هوش مصنوعی: ماشین لرنینگ ما دیدن فرمایید