


دستهبندی نشده
تولید داده های زیستی، روشهای ترکیب داده و Multi-Omics
درباره تولید داده های زیستی، روشهای ترکیب داده و Multi-Omics
قبل از اینکه به سراغ پیادهسازی روشهای سیستم بیولوژی برویم، در ابتدا باید یک سوال زیستی داشته باشیم. این سوال زیستی هرچیزی میتواند باشد. مثلا ممکن است شما به دنبال شناسایی چندین ژن مهم دخیل در سرطان پانکراس باشید، یا میخواهید بدانید چرا دستهای از بیماران مبتلا به AML، به دارو خاصی پاسخ نمیدهند، اما گروهی دیگر جواب خوبی میگیرند و درمان میشوند.
سوالات تنها به حوزه درمان منحصر نمیشود و شما میتوانید این سوالات را در صنعت نیز بپرسید. یعنی ممکن است این سوال را داشته باشید که چطور میتوانم تولید اتانول را در مخمر بیشینه کنم و یا اینکه چطور محیط کشت را برای سلولها بهینه کنم تا رشد خوبی داشته باشند. ممکن است علاقه داشته باشید با کمترین حذف ژنی، سویهای صنعتی را طراحی کنید که محصول موردنظر شما را تولید کند.
گاهی اوقات سوالات ممکن است جنبههای زیستمحیطی یا کشاورزی داشته باشد. مثلا ممکن است شما علاقهمند باشید تغییرات میکروبها را در خاک یا در ارتباط با یک گیاه بررسی کنید. شناسایی این دینامیک به شما در تولید محصول کشاورزی بهتر و بهینهتر کمک خواهد کرد یا اینکه میتوانید با کنترل جمعیت باکتریها، از ورود پاتوژنها به محیط جلوگیری کنید. همچنین با طراحی جمعی از میکروبها به کمک سیستم بیولوژی ضایعات پلاستیکی را تجزیه کنید تا از محیط زیست محافظت کنید.

پس همینطور که به نظر میرسد، ما سوالات زیستی مختلفی را میتوانیم طرح کنیم و مرزی برای آن وجود ندارد. قدم بعدی، تولید داده است. شاید بتوان هر سوالی را پرسید، اما آیا برای پاسخ به آن میتوانیم دادههای مناسبی جمع کنیم؟ اصلا داده مناسب چیست؟
دستگاههای زیادی برای تولید دادههای زیستی وجود دارد. از PCR گرفته تا NGS، دادهای که تولید میشود همان داده زیستی است. یعنی شما یک کمیت زیستی را اندازه گرفتهاید و آن را به یک عدد تبدیل کردهاید. پس اولین قدم شناسایی یک دستگاه مناسب برای تولید داده است. سوال بعدی که پیش میآید این است که چقدر باید داده تولید کنیم و اینکه آیا دستگاههای موجود در بازار توانایی تولید این داده را دارند؟
باید گفت که اگر به دنبال رویکرد سیستم بیولوژی هستیم، بایستی به سمت روشها و دستگاههایی برویم که به میزان بالایی داده تولید میکنند. هدف اصلی این رویکرد دوری از bias است. پس اگر بتوانیم دادههای زیادی جمع کنیم، بدون اینکه هیچ فرض اولیهای داشته باشیم، میتوانیم تا حدی خود را از دست قضاوت رها کنیم. این دستگاهها در حال پیشرفت بوده و میتوانند در مدت زمان کوتاهی دادههای زیادی تولید کنند، اما باز هم ما همه چیز را در مورد سلولها نمیدانیم. پیشرفتی که نسبت به سالهای گذشته رخ داده، حجم زیادی از دادهها را تولید کرده است که باید به کمک روشهای جدید تحلیل شود. روشهایی که پس از جمعآوری داده، به ارائه نظریه میپردازد.

تولید دادهها به کمک تکنولوژیهای High throughput یا توان بالا، در حوزه اومیکس (Omics) قرار میگیرد. این دادهها در مراحل بعدی توسط تحلیلها و مدلسازی مبتنی بر سیستم بیولوژی مورد بررسی قرار میگیرند. این دادهها تحت عنوان دادههای بزرگ مقیاس، با توان بالا و دادههای اومیکس شناخته میشوند.
دیتای اومیکس یا اومیک در سطوح مختلفی به دست میآید تا بتواند دیدی جامع از سیستمهای زیستی به ما ارائه کند. دادههای اومیک به کمک دستگاههای پیشرفته با توان بالا به دست میآیند که میتواند اطلاعاتی را در سطوح ژنوم، ترنسکریپتوم، پروتئوم، متابولوم و غیره را فراهم کند.
این مسیر با ورود تکنیکهای ریزآرایه یا میکرواری آغاز شد که به کمک هیبریدیزاسیون پروبهای DNA انجام میشد. از این روش برای بررسی پروفایل بیانی mRNA نیز استفاده میشود که در آن پس از استخراج، mRNA به cDNA تبدیل میشود تا بتوانیم آن را روی چیپ ران کنیم. سپس نتایج حاصل از میکرواری تحلیل خواهد شد.
تکنیکهای دیگری که در اومیکس استفاده میشود توالییابی ژنوم است که شامل نسل اول، نسل دوم و سوم و توالییابی عمیق میشود. بررسی پلی مورفیسم تک نوکلئوتیدی، CNV و اگزونها نیز اطلاعاتی را در اختیار ما قرار میدهد. CHiP-seq نیز ارتباط پروتئین متصل شده به ماده ژنتیک را بررسی میکند.
تکنیک مهم دیگر RNA-seq است که توالییابی cDNA انجام میشود و دقت بهتری نسبت به میکرواری دارد. این روش دید کمی نیز به ما میدهد و واریانتهای مختلف splicing را نیز شناسایی می کند. به همین دلیل میتواند جای میکرواری را در آینده بگیرد. بااینحال، میکرواری از این روش ارزانتر است. بررسی mRNAها در حوزه ترنسکریپتومیکس از علم اومیکس قرار گرفته و بررسی میشود.
بررسی متیلاسیون DNA نیز در حوزه اپیژنومیکس قرار میگیرد. با اضافهشدن گروه متیل به سیتوزین، معمولاً ژن مهار شده و تنظیم بیان ژن رخ میدهد. روشهای توالییابی بیسولفیت به بررسی ژنهای متیلهشده در اومیکس میپردازد.
MicroRNAها توالیهای کوتاهی در حدود 21 تا 25 هستند که بیان ژن را میتواند با مهارکردن آن تنظیم کند. به همین دلیل در تنظیم بیان ژن اثر دارد. این نوع از RNAها را نیز میتوان به کمک روشهای توالییابی RNA-seq بررسی نمود. هرکدام از این miRNAها میتواند تعداد زیادی از ژنها را تحتتأثیر قرار دهد پس اطلاعات این بخش از اومیکس نیز برای سیستم بیولوژی اهمیت دارد.
دسته دیگری از فناوریهای اومیکس به پروتئومیکس اختصاص دارد که به پروتئینهای سلول مربوط میشود تا فعالیت آنها را بررسی کند. اندازهگیری سطوح پروتئین به کمک طیفسنج جرمی یا mass spectrometry انجام میشود. در این تکنیک، پروتئینها بهصورت گاز درآمده و در یک میدان حرکت میکنند. سپس بر اساس جرم مولکولی بررسی میشوند تا مشخص شود که از چه اسیدآمینههایی تشکیل شدهاند. به کمک این روش میتوانیم تغییرات شیمیایی پس از ترجمه یا PTM پروتئینها را نیز بررسی کنیم.
دسته دیگری از مطالعات اومیکس در حوزه متابولومیکس قرار میگیرد. در این روش سعی میشود که تمامی متابولیتهای سلول در یک شرایط مکانی و زمانی خاص شناسایی شود. در این روش نیز مانند روش قبلی ممکن است از روشهای طیفسنجی جرمی یا NMR استفاده شود. این روش به ما کمک میکند که تغییرات فنوتیپی را شناسایی کنیم. مثلاً ممکن است جهش در یک پروتئین خیلی جزئی باشد، اما فعالیت پروتئین را افزایش دهد. این افزایش فعالیت تنها در سطح متابولومیک خود را نشان میدهد یا حتی ممکن است پروتئین طی یک جهش زیاد تولید شود، اما فعالیت زیادی نداشته باشد.
اومیک در حوزههای دیگر مانند بررسی میکروبیومها نیز کاربرد دارد. به کمک بررسیهای متاژنومیکس، میتوان توالیهای ژنتیکی میکروبیوم را مورد بررسی قرار داد و جمعیتهای میکروبی را از نظر فراوانی و عملکرد بررسی کرد. اگر دادههای ترنسکریپتوم در میکروبیوم بررسی شود، اصطلاحی که به آن اطلاق میشود، متاترنسکریپتومیکس خواهد بود.
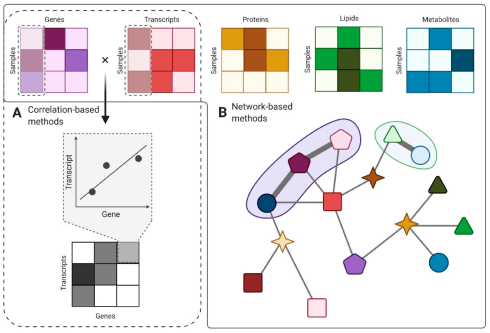
مساله دیگری که امروزه به آن باید توجه کنیم، کنار هم گذاشتن دادههای مختلف اومیکس است. بررسی دادههای اومیکس در یک سطح، مثلا ژنوم، ما را از دیدگاهها در سطوح دیگر دور میکند. همانطور که میدانیم، تمامی ژنها بیان نمیشوند و ممکن است به دلایل مختلفی خاموش شوند یا میزان بیان متفاوتی بگیرند. برای یافتن این دیتا باید به سراغ ترنسکریپوم یا همان دیتا در سطح بیانی برویم. قدمهای بعدی را نیز میتوانیم برداریم. مثلا ممکن است هر mRNA به پروتئین تبدیل نشود، یا بررسی تغییرات متابولیتها اهمیت بالایی برای درک عملکرد سلول داشته باشد.

اینجاست که نگاه کردن به یک سطح از اومیکس کافی نیست و باید رویکرد خود را تغییر دهیم. بایستی سعی کنیم دیتا در سطوح مختلف را کنار هم بیاوریم و روشهای multi-omics (چندین اومیکس) را توسعه دهیم. با جمعآوری دادهها در تمامی این سطوح، باید از الگوریتمهایی برای ترکیب این دادهها استفاده کنیم. جنس دادهها متفاوت بوده و حتی تعداد بیوملکولهای خوانده شده متفاوت است. اینجاست که الگوریتمهای ترکیب داده به ما کمک میکنند تحلیل مناسبی را ارائه داده و دادهها را ترکیب کنیم.
روشهای انتخاب ویژگی feature selection و استخراج ویژگی feature extraction به ما این امکان را میدهند که ابعاد دادهها را کم کنیم، و تنها ویژگیهایی را برای ترکیب نگه داریم که اطلاعات خوبی درخود دارند. همچنین برای ترکیب دادهها میتوان از روشهای دیگر کاهش بعد مانند autoencoder نیز استفاده کرد که فضای ویژگی را به ابعاد کوچکتری تبدیل میکند. البته باید به کمک روشهای دیگر، خروجی این روشها تحلیل شود تا به یک معنای زیستی برسیم.
به کمک روشهای مبتنی بر گراف نیز میتوان دادههای اومیکس را با هم ترکیب کرد. همان طور که میدانیم، بیوملکولها با یکدیگر در مسیرهای زیستی یا pathway در ارتباط هستند. پس وقتی بتوانیم از دیتای مسیرها استفاده کنیم، میتوانیم ارتباط دادههای مختلف را با هم شناسایی کنیم و چندین دیتاست را با هم ترکیب کنیم.